Edge AI & Federated Learning: Revolutionizing IoT Data Processing
Explore how Edge AI and Federated Learning are transforming the Internet of Things, addressing challenges like privacy, latency, and bandwidth by processing data closer to its source, especially for resource-constrained devices. Discover the future of intelligent IoT.
The digital world is expanding at an unprecedented rate, driven by billions of interconnected devices forming the Internet of Things (IoT). From smartwatches tracking our health to industrial sensors optimizing factory floors, these devices generate an ocean of data. Traditionally, processing this data meant sending it to centralized cloud servers. However, this approach is increasingly challenged by concerns around privacy, network bandwidth, latency, and the sheer scale of data. Enter the powerful synergy of Edge AI and Federated Learning (FL), offering a paradigm shift in how intelligence is deployed and managed across the IoT landscape, especially for resource-constrained devices.
The Rise of Edge AI and the IoT Data Deluge
The IoT ecosystem is a sprawling network of diverse devices, each with unique capabilities and limitations. These devices, often referred to as "edge devices," are the front lines of data generation. They include everything from tiny sensors with minimal processing power to more sophisticated smart cameras and industrial gateways.
Edge AI refers to the deployment of artificial intelligence models directly on these edge devices or on nearby edge servers. Instead of constantly streaming raw data to a distant cloud for analysis, Edge AI processes data locally. This brings several immediate advantages:
- Reduced Latency: Decisions can be made in milliseconds, crucial for real-time applications like autonomous driving or industrial control.
- Lower Bandwidth Consumption: Only processed insights or necessary data snippets are sent to the cloud, significantly easing network strain.
- Enhanced Reliability: Operations can continue even with intermittent or no network connectivity.
- Improved Privacy: Sensitive data remains local, reducing exposure to potential breaches during transit or in centralized storage.
Despite these benefits, training AI models on edge devices presents a formidable challenge. Edge devices are often resource-constrained, meaning they have limited computational power, memory, storage, and battery life. Furthermore, they operate in diverse environments, leading to highly varied and often sensitive local datasets. This is where Federated Learning steps in as a game-changer.
Unpacking Federated Learning: A Collaborative Privacy-Preserving Approach
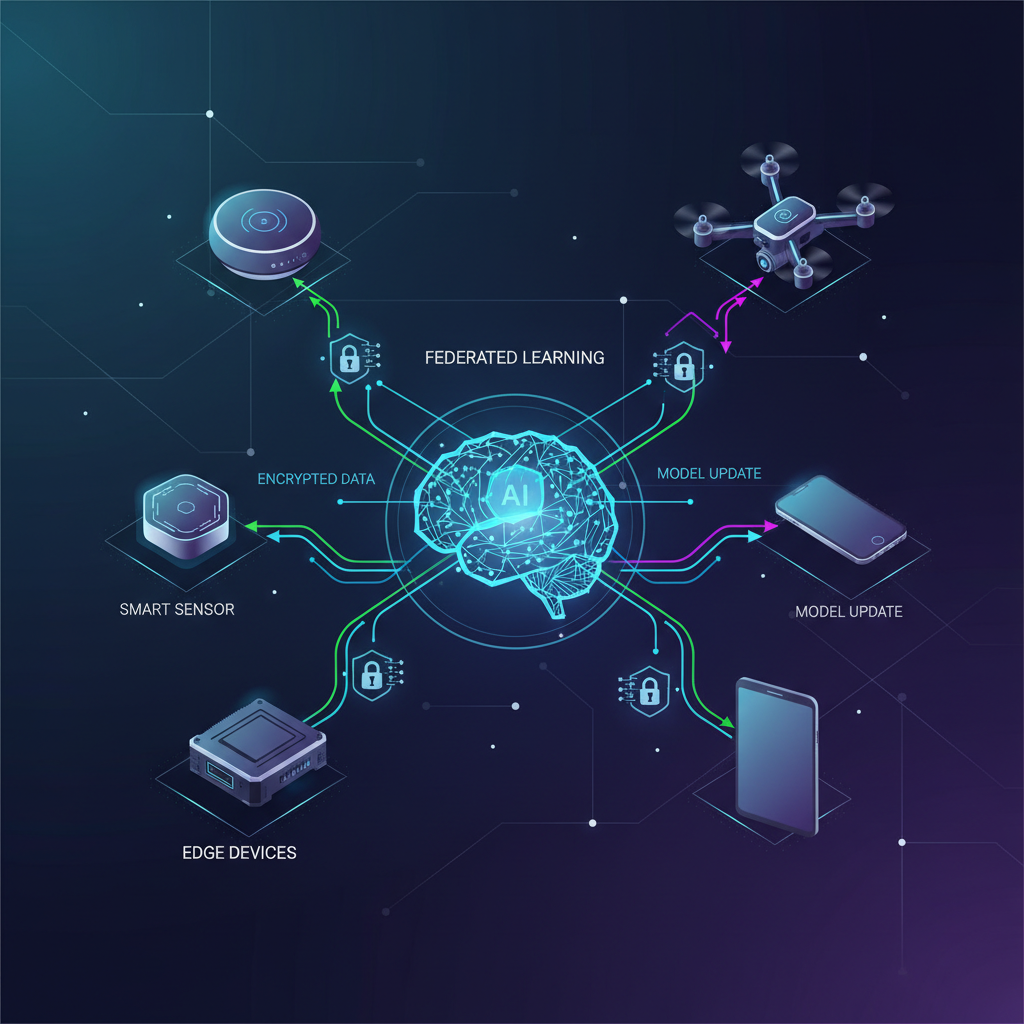
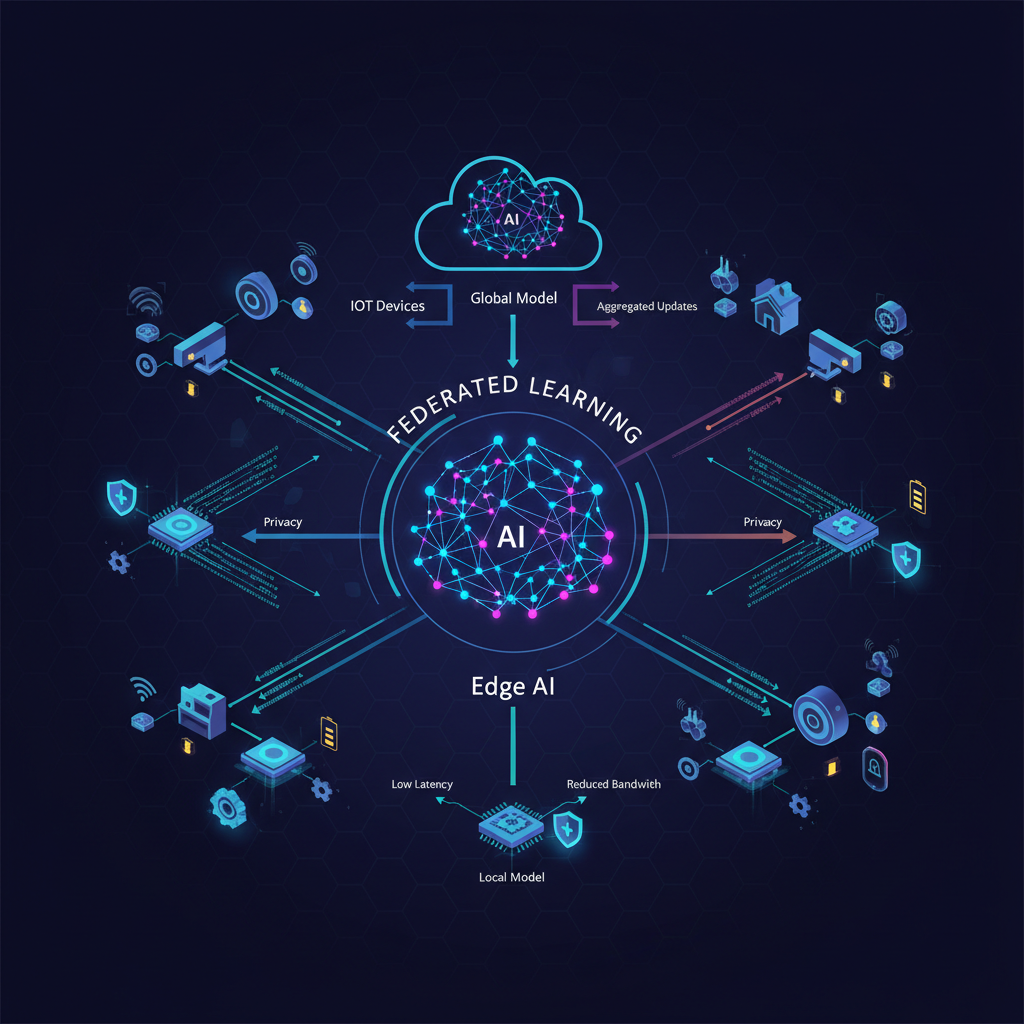
Federated Learning (FL) is a distributed machine learning paradigm that enables multiple edge devices (clients) to collaboratively train a shared global model without ever exchanging their raw data. Instead, the core idea is to bring the model to the data, rather than the data to the model.
Here's a simplified breakdown of how FL typically works:
- Global Model Distribution: A central server initializes a global machine learning model (e.g., a neural network) and sends it to a subset of participating edge devices.
- Local Training: Each selected device trains this model locally using its own private dataset. During this phase, only the device's local data is accessed, and no raw data leaves the device.
- Model Update Transmission: After local training, instead of sending its raw data, each device sends only the model updates (e.g., gradients, weight differences, or updated model parameters) back to the central server. These updates are typically much smaller in size than the raw data itself.
- Global Model Aggregation: The central server receives model updates from multiple devices. It then aggregates these updates, often using techniques like Federated Averaging (FedAvg), to create an improved version of the global model.
- Iteration: The updated global model is then sent back to the devices for another round of local training, and the process repeats. This iterative cycle continues until the global model reaches a desired performance level.
The beauty of FL lies in its ability to foster collaborative intelligence while upholding a strong commitment to data privacy. No individual device's raw data is ever exposed to the central server or other devices, making it an ideal solution for scenarios involving sensitive information.
Why Federated Learning is Crucial for Resource-Constrained IoT
The intersection of FL with resource-constrained IoT devices is a hotbed of innovation and research, driven by several critical factors:
1. Unprecedented Privacy and Data Sovereignty
In an era of increasing data privacy regulations (like GDPR, CCPA, HIPAA) and heightened public awareness, the traditional cloud-centric model of data collection and training is becoming unsustainable for sensitive IoT applications. Imagine wearable health monitors, smart home assistants, or industrial machinery generating proprietary operational data.
FL inherently addresses this by ensuring that sensitive data never leaves the device. For instance, a fleet of medical IoT devices can collaboratively learn to detect early signs of a disease without patient health records ever being exposed to a central server. This "privacy-by-design" approach is a cornerstone of FL's appeal.
2. Overcoming Bandwidth and Latency Bottlenecks
IoT devices often operate in environments with limited, expensive, or intermittent network connectivity. Transmitting gigabytes of raw sensor data from thousands or millions of devices to the cloud for training is often impractical, costly, and leads to unacceptable latency for real-time applications.
FL significantly alleviates this by only transmitting small model updates, not raw data. This reduction in communication overhead is vital for:
- Remote Monitoring: Devices in rural areas or harsh industrial environments can participate in training without requiring high-speed, constant connections.
- Real-time Decision Making: Lower latency due to local processing and reduced data transfer enables faster responses for critical applications like autonomous systems.
- Cost Efficiency: Reduced bandwidth usage translates directly into lower operational costs for large-scale IoT deployments.
3. Scalability for a Billion-Device World
The sheer number of IoT devices deployed globally is staggering and continues to grow exponentially. Centralized training approaches struggle with this scale, requiring massive data centers and complex ingestion pipelines. FL offers a naturally scalable solution:
- Distributed Computation: The computational burden of training is distributed across potentially millions of edge devices, leveraging their collective processing power.
- Decentralized Data Management: No single point of failure for data storage or processing, enhancing system robustness.
4. Personalization at the Edge
While FL trains a global model, it also allows for personalized experiences. Once a robust global model is learned, individual devices can further fine-tune this model using their specific local data. This leads to:
- Tailored User Experiences: A smart home assistant can learn individual family member preferences without sharing voice data. A mobile keyboard can predict words based on a user's unique typing patterns.
- Adaptability: Devices can adapt to their specific environmental conditions or user behaviors, improving performance beyond a generic global model.
5. Addressing Resource Constraints: A Research Frontier
The "resource-constrained" aspect is where much of the cutting-edge research in FL for IoT is focused. Edge devices typically have:
- Limited CPU/GPU: Often low-power processors, sometimes without dedicated AI accelerators.
- Small Memory Footprint: Restricted RAM and storage.
- Battery Dependence: Energy efficiency is paramount for device longevity.
To enable FL on such devices, researchers are developing innovative techniques:
- Communication Efficiency:
- Sparsification: Sending only the most significant model updates, reducing the number of parameters transmitted.
- Quantization: Reducing the precision of model parameters (e.g., from 32-bit floats to 8-bit integers) to shrink update size.
- Compression: Using various data compression algorithms on the model updates.
- Federated Dropout/Sampling: Only a subset of devices or model layers participate in each round to reduce communication.
- Computation Efficiency:
- Lightweight Model Architectures: Designing AI models specifically for edge devices (e.g., MobileNets, EfficientNets, TinyML models) that have fewer parameters and require less computation.
- Knowledge Distillation: Training a smaller, simpler "student" model on the predictions of a larger, more complex "teacher" model, making it suitable for edge deployment.
- Pruning: Removing redundant connections or neurons from neural networks to reduce model size and computational load.
- Early Exit Networks: Models that can make predictions at intermediate layers if confidence is high, saving computation.
- Energy Efficiency: Optimizing when and how often devices communicate and train to minimize power consumption, extending battery life. This often involves intelligent scheduling and adaptive training strategies.
6. Navigating Data Heterogeneity (Non-IID Data)
A significant challenge in FL, particularly in IoT, is that data across devices is rarely "Independent and Identically Distributed" (IID). This means different devices might have vastly different data distributions, quantities, or labels. For example, a smart camera in a park will see different objects than one in a factory.
If not handled correctly, non-IID data can lead to model drift, where the global model performs poorly on individual devices or converges slowly. Active research areas include:
- Advanced Aggregation Algorithms: Beyond basic FedAvg, methods like FedProx, SCAFFOLD, FedAvgM, and FedNova aim to improve convergence and fairness on non-IID data.
- Personalization Techniques: Meta-learning and transfer learning approaches that allow the global model to quickly adapt to local data characteristics.
- Client Selection Strategies: Intelligently selecting which devices participate in each training round based on data distribution, resource availability, or contribution to model improvement.
7. Enhancing Security and Robustness
While FL improves privacy, it introduces new security considerations. Malicious devices could send poisoned updates to degrade or bias the global model (poisoning attacks), or adversaries might try to reconstruct sensitive data from shared gradients (inference attacks).
Research focuses on:
- Differential Privacy (DP): Adding carefully calibrated noise to model updates to mathematically guarantee privacy, making it nearly impossible to infer individual data points.
- Secure Multi-Party Computation (SMC): Cryptographic techniques that allow multiple parties to jointly compute a function over their inputs while keeping those inputs private.
- Robust Aggregation Methods: Algorithms designed to detect and mitigate the impact of malicious or outlier updates from compromised devices.
- Homomorphic Encryption: Performing computations directly on encrypted data, offering strong privacy guarantees but with significant computational overhead.
Practical Applications: Where FL for IoT Shines
The theoretical advantages of FL for resource-constrained IoT devices translate into compelling real-world use cases across various industries:
Smart Healthcare
- Wearable Diagnostics: Smartwatches and medical sensors can collaboratively train models to predict health conditions (e.g., arrhythmia, diabetes onset) from individual physiological data without patient records leaving the device. This respects strict privacy regulations like HIPAA.
- Personalized Treatment: Hospitals can share insights from patient data to improve diagnostic models without sharing raw patient information, leading to better, more personalized care.
Autonomous Vehicles
- Collaborative Perception: Fleets of vehicles can collaboratively learn to identify road hazards, pedestrians, and traffic signs from diverse real-world driving data. Each vehicle contributes its unique sensor data (camera, LiDAR, radar) to improve the global perception model, without sharing sensitive location or detailed environmental scans with a central entity.
- Predictive Maintenance: Vehicles can share anonymized diagnostic data to train models that predict component failures, improving safety and reducing downtime.
Smart Homes and Cities
- Personalized Home Automation: Smart cameras can learn to differentiate between family members and strangers, or identify anomalous events (e.g., package delivery, intruders) based on local household data, without streaming video to the cloud.
- Energy Optimization: Smart thermostats and appliances can collaboratively learn optimal energy usage patterns for a neighborhood or city block, adapting to local conditions and preferences while maintaining individual household privacy.
- Environmental Monitoring: Smart city sensors (air quality, noise levels, traffic flow) can train localized models to detect patterns and anomalies, contributing to a global understanding of urban environments without centralizing all raw data.
Industrial IoT (IIoT) and Predictive Maintenance
- Factory Floor Optimization: Machines in a factory can collaboratively train models to predict equipment failures, optimize production parameters, or detect anomalies in operational data. This is crucial for proprietary manufacturing processes where data cannot leave the factory floor due to intellectual property concerns.
- Supply Chain Analytics: Different entities in a supply chain can contribute to a shared model for demand forecasting or logistics optimization, without revealing sensitive business data to competitors or third parties.
Mobile Devices and Personal Assistants
- Next-Word Prediction and Speech Recognition: Mobile keyboards and voice assistants (like Google's Gboard or Apple's Siri) already leverage FL to improve their models. They learn from user typing patterns and voice commands directly on the device, enhancing personalization and accuracy without sending sensitive personal input to cloud servers.
- Image Recognition: On-device photo categorization or object recognition can be improved by collaboratively learning from user-tagged images, keeping personal photo libraries private.
Key Challenges and Future Directions
While FL for resource-constrained IoT devices holds immense promise, several challenges remain and represent active areas of research:
- System Heterogeneity: Managing devices with vastly different computational power, memory, network connectivity, and even operating systems is complex. Strategies for fair resource allocation and adaptive training schedules are crucial.
- Communication Overhead (Still a Factor): Even with compression, frequent updates of large models can still be a bottleneck, especially for extremely low-bandwidth scenarios. Research into asynchronous FL and more efficient communication protocols is ongoing.
- Security and Trust: While progress has been made, ensuring the integrity of the global model against sophisticated poisoning attacks and protecting against advanced privacy leakage techniques (e.g., membership inference attacks) remains a high priority.
- Evaluation Metrics: Traditional ML evaluation metrics don't fully capture the nuances of FL, especially regarding privacy guarantees, fairness across diverse devices, and resource consumption. New, holistic evaluation frameworks are needed.
- Deployment and Orchestration: Practically deploying, managing, monitoring, and updating FL pipelines across millions of diverse edge devices in the field is a significant engineering challenge. This requires robust orchestration platforms and device management solutions.
- Integration with TinyML: Combining FL with ultra-low-power, highly optimized TinyML models for truly embedded, "always-on" applications will unlock new possibilities for pervasive intelligence.
- Fairness and Bias: Ensuring that the global model performs equitably across all participating devices, especially when data distributions are highly skewed, is critical to avoid algorithmic bias.
Conclusion: The Intelligent Edge is Here
Federated Learning for resource-constrained edge devices in IoT is not just a theoretical concept; it's a rapidly maturing field that is fundamentally reshaping how we think about AI deployment. By meticulously balancing privacy, efficiency, and performance, FL empowers the vast network of IoT devices to become active participants in the creation of collective intelligence, rather than just passive data collectors.
For AI practitioners and enthusiasts, this domain offers a unique blend of cutting-edge research and immense practical impact. Open-source frameworks like TensorFlow Federated, PySyft (OpenMined), and Flower provide accessible platforms to experiment with FL, allowing for hands-on exploration of its potential. As the number of connected devices continues to soar and privacy concerns intensify, mastering the intricacies of Federated Learning at the intelligent edge will be paramount for building the next generation of secure, efficient, and truly smart IoT applications. The future of AI is distributed, collaborative, and privacy-aware, and it's unfolding right at the edge.