Federated Learning: The Future of Edge AI and IoT Data Privacy
Explore how Federated Learning is revolutionizing Edge AI by enabling collaborative model training on IoT devices while keeping sensitive data localized. Discover its role in overcoming challenges like privacy, bandwidth, and computational limits.
The digital world is expanding beyond our screens and into every corner of our physical environment. Billions of interconnected devices, from smart sensors in factories to health monitors on our wrists, form the Internet of Things (IoT). These devices generate an unprecedented deluge of data at the "edge" of the network. The ability to extract intelligence from this data, directly where it's generated, is the promise of Edge AI. However, deploying sophisticated AI models on resource-constrained IoT devices presents a unique set of challenges, particularly concerning data privacy, network bandwidth, and computational limitations.
Enter Federated Learning (FL), a paradigm that is rapidly emerging as a transformative solution. FL allows multiple edge devices to collaboratively train a shared machine learning model while keeping their raw training data localized. This innovative approach addresses many of the core hurdles of Edge AI, making it a cornerstone for the future of intelligent IoT ecosystems.
The Imperative of Edge AI and the Federated Learning Promise
The traditional cloud-centric AI model, where all data is shipped to a central server for training and inference, is increasingly unsustainable for IoT. Consider the implications:
- Data Privacy and Security: Sending sensitive patient data from a wearable health device or proprietary industrial data from a factory floor to a central cloud raises significant privacy and security concerns. Regulatory frameworks like GDPR and CCPA further emphasize the need for data localization.
- Network Bandwidth and Latency: Transmitting petabytes of raw sensor data from millions of devices to the cloud is a monumental task, straining network infrastructure and introducing unacceptable latency for real-time applications (e.g., autonomous vehicles).
- Resource Constraints: While edge devices are becoming more powerful, they still operate under strict limitations regarding battery life, processing power, and memory compared to cloud data centers.
- Offline Operation: Many IoT applications require intelligence even when internet connectivity is intermittent or unavailable.
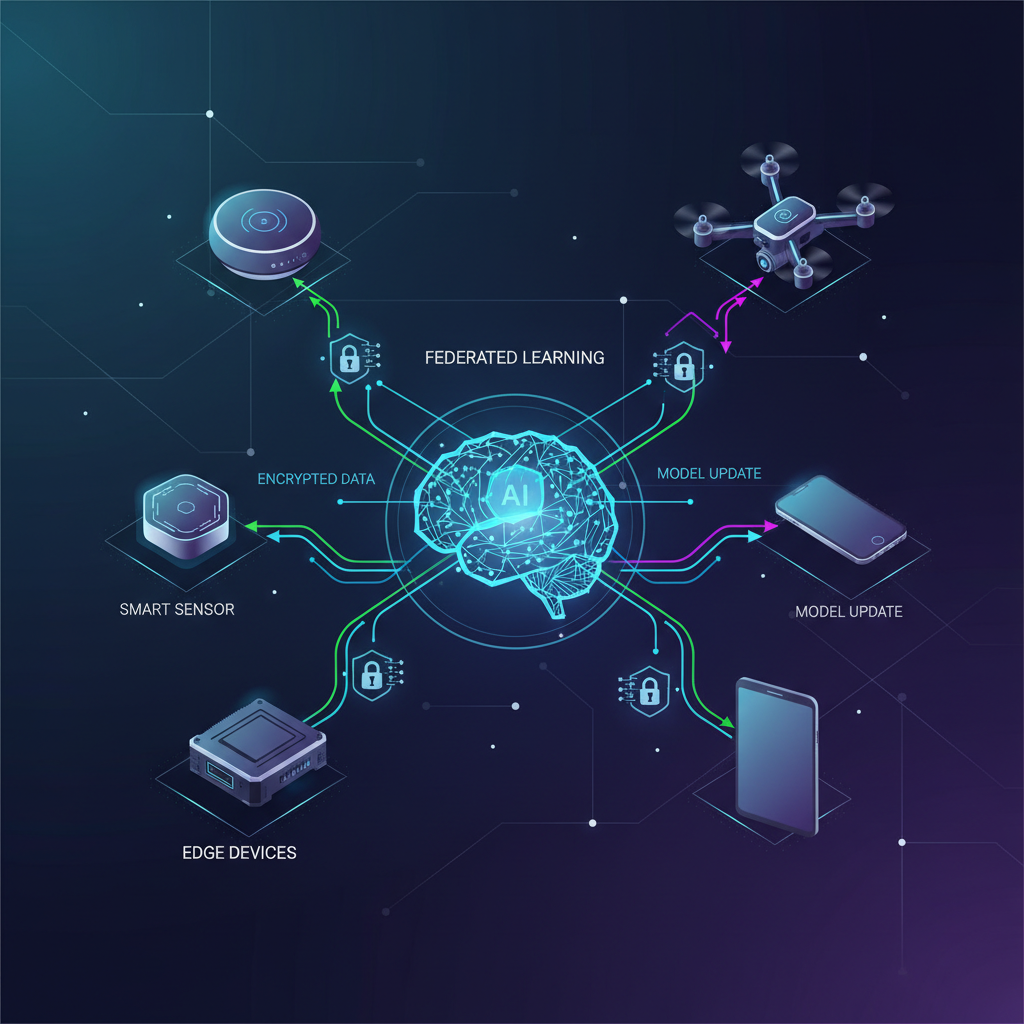
Federated Learning directly tackles these issues by shifting the "where" of AI training. Instead of data going to the model, the model (or its updates) comes to the data. Devices train models locally on their own data, and only aggregated model updates (e.g., weight gradients) are sent to a central server for consolidation. This preserves data privacy, reduces communication overhead, and leverages distributed computational resources.
Google's Gboard, which uses FL to improve next-word prediction without sending user typing data to the cloud, is a well-known example. But the potential extends far beyond, into industrial IoT, smart cities, healthcare, and autonomous systems.
Core Challenges of Federated Learning on Resource-Constrained IoT Edge Devices
While FL offers compelling advantages, its deployment on the heterogeneous and often unforgiving landscape of IoT edge devices introduces significant complexities.
1. Resource Heterogeneity
IoT devices are incredibly diverse. A smart light bulb has vastly different computational capabilities, battery life, and network connectivity than an industrial robot or a self-driving car.
- Compute Power: Some devices might have dedicated AI accelerators (NPUs, TPUs), while others rely on low-power microcontrollers.
- Memory: Limited RAM can restrict model size and the complexity of local training tasks.
- Battery Life: Continuous training can quickly drain batteries, making participation unsustainable for many devices.
- Network Connectivity: Devices might experience unreliable Wi-Fi, cellular (5G, LTE-M, NB-IoT), or even short-range protocols (Bluetooth, Zigbee) with varying bandwidth and latency.
This heterogeneity makes it challenging to orchestrate training rounds, as faster devices might finish quickly while slower ones lag, potentially holding up the aggregation process.
2. Data Heterogeneity (Non-IID Data)
This is arguably the most significant research challenge in FL. In traditional distributed machine learning, data is often assumed to be independently and identically distributed (IID) across participants. However, in IoT, this is rarely the case.
- Sensor Drift: A temperature sensor in one room will record different data than one in another.
- User Behavior: Smart home devices reflect individual user habits.
- Geographical Variation: Traffic patterns in one city differ from another.
When local models are trained on non-IID data, their updates can diverge significantly. Simple aggregation (like averaging) of these diverse updates can lead to:
- Model Drift: The global model's performance degrades or converges slowly.
- Fairness Issues: The global model might perform poorly on data from devices whose local distributions are underrepresented in the aggregated model.
3. Communication Overhead
While FL significantly reduces data transmission compared to centralized training, sending model updates (gradients or weights) can still be costly, especially for large models or frequent training rounds involving millions of devices.
- Upload Bottleneck: Edge devices often have asymmetric bandwidth, with much slower upload speeds than download speeds.
- Energy Consumption: Radio transmission is a major power drain for battery-operated devices.
- Scalability: Managing and aggregating updates from millions of devices simultaneously presents a significant orchestration challenge for the central server.
4. Security & Privacy Attacks
While FL enhances privacy by keeping raw data local, it's not a silver bullet. New attack vectors emerge:
- Inference Attacks: Malicious actors might infer sensitive information about individual device data from shared model updates or the aggregated model itself.
- Poisoning Attacks: Malicious devices can send deliberately corrupted model updates to degrade the global model's performance or inject backdoors.
- Model Inversion Attacks: Reconstructing training data samples from the shared model parameters.
5. Fault Tolerance & Robustness
IoT environments are inherently dynamic and unreliable.
- Device Dropouts: Devices can go offline due to battery depletion, network loss, or physical damage.
- Unreliable Connections: Intermittent connectivity can disrupt training rounds.
- Malicious Participants: Devices might intentionally send incorrect updates or refuse to participate.
The FL system must be robust enough to handle these failures without compromising the global model's integrity or convergence.
6. Model Personalization
A single global model might not be optimal for all devices, especially with highly non-IID data. For example, a smart home assistant might need to recognize a specific user's voice patterns, which differ from the global average. Balancing the benefits of a shared global model with the need for personalized local models is a complex trade-off.
Innovative Solutions and Techniques
Researchers and practitioners are developing a rich array of techniques to overcome these FL challenges at the edge.
1. Communication Efficiency
Reducing the size and frequency of model updates is crucial.
- Quantization: Reducing the precision of model parameters (e.g., from 32-bit floats to 8-bit integers or even binary) before transmission. This significantly shrinks update size with minimal impact on accuracy.
- Sparsification: Sending only a subset of the most important model parameters (e.g., those that changed most significantly) or using sparse representations.
- Federated Averaging (FedAvg) Variants: The foundational FedAvg algorithm simply averages local model weights. More advanced variants aim to improve convergence and handle heterogeneity:
- FedProx: Adds a proximal term to the local objective function, penalizing divergence from the global model, which helps stabilize training with non-IID data.
- SCAFFOLD: Uses control variates to correct for client drift caused by local data heterogeneity, leading to faster convergence.
- FedNova: Normalizes local updates to account for varying numbers of local steps taken by clients, improving fairness and convergence.
- Asynchronous FL: Instead of waiting for all selected clients to complete a round, the server aggregates updates as they arrive, allowing faster clients to contribute more frequently and reducing idle time.
2. Addressing Non-IID Data
This area is a hotbed of research, focusing on making FL models more robust and fair across diverse data distributions.
- Personalized FL (pFL): Instead of a single global model, pFL aims to create models tailored for individual devices or groups.
- Meta-learning: Training a global model that can be quickly adapted (fine-tuned) to new local data with minimal local steps.
- Transfer Learning: Using the global model as a feature extractor or pre-trained base, which is then fine-tuned on local data.
- Local Fine-tuning: After receiving a global model, devices perform additional local training steps to adapt it to their specific data.
- Clustered FL: Grouping devices with similar data distributions into clusters. Each cluster then trains its own FL model, leading to multiple specialized global models. This requires effective clustering algorithms that can operate without direct access to raw data.
- Knowledge Distillation in FL: A global "teacher" model can guide the training of local "student" models, or vice-versa. For example, a powerful central model can distill its knowledge into smaller, more efficient edge models.
3. Privacy & Security Enhancements
Strengthening FL's inherent privacy benefits and mitigating new attack vectors.
- Differential Privacy (DP): Adding carefully calibrated noise to model updates before sending them to the server. This provides a mathematical guarantee that no single individual's data can be inferred from the aggregated update, even if an attacker has auxiliary information. The trade-off is a slight reduction in model accuracy.
- Secure Multi-Party Computation (SMC): Allows multiple parties to jointly compute a function over their private inputs without revealing those inputs to each other. In FL, SMC can be used to securely aggregate model updates without the central server or any individual client seeing the raw updates from other clients.
- Homomorphic Encryption (HE): A powerful cryptographic technique that allows computations to be performed on encrypted data without decrypting it. This could enable the server to aggregate encrypted model updates without ever seeing the unencrypted values. HE is computationally intensive but becoming more practical with hardware acceleration.
- Blockchain for FL: A decentralized ledger can be used to record and verify model updates, ensuring transparency, immutability, and accountability. It can also manage client selection and incentivize participation.
4. Resource Management & Optimization
Optimizing training for the diverse capabilities of edge devices.
- Client Selection Strategies: Dynamically choosing which devices participate in each training round based on criteria like:
- Resource Availability: Devices with sufficient battery, compute, and network bandwidth.
- Data Quality/Quantity: Prioritizing devices with fresh, diverse, or abundant data.
- Fairness: Ensuring all eligible devices get a chance to participate over time.
- Reputation: Excluding or penalizing unreliable or malicious clients.
- On-device Training Optimization:
- Quantization-aware Training: Training models with quantization in mind from the start, leading to models that are robust to lower precision.
- Pruning: Removing redundant weights or connections from neural networks to reduce model size and computational requirements.
- Efficient Model Architectures: Designing neural networks specifically for edge deployment, such as MobileNet, EfficientNet, or ShuffleNet, which balance accuracy with computational efficiency.
Emerging Architectures & Paradigms
The FL landscape is continually evolving, giving rise to more sophisticated deployment models.
1. Hierarchical Federated Learning (HFL)
For large-scale IoT deployments, a single central server managing millions of devices can become a bottleneck. HFL introduces multiple aggregation layers:
- Local Aggregation: Edge devices first aggregate their models at a local gateway (e.g., a smart home hub, a factory edge server).
- Regional Aggregation: These local gateways then send their aggregated updates to a regional server.
- Central Aggregation: Finally, regional servers send updates to a central cloud server.
This multi-tier approach reduces the load on the central server, improves communication efficiency by aggregating closer to the data source, and can provide localized intelligence at different levels.
2. Cross-Device vs. Cross-Silo FL
- Cross-Device FL: The focus of this discussion, involving a large number of resource-constrained mobile phones, IoT sensors, etc., each contributing a small amount of data. Challenges include unreliable connectivity, device dropouts, and significant data heterogeneity.
- Cross-Silo FL: Involves a smaller number of organizations (silos), each with large, high-quality datasets (e.g., hospitals, banks, industrial enterprises). These silos typically have stable network connections and more computational resources. The challenges here often revolve around trust, regulatory compliance, and complex data schemas.
While distinct, insights from one often inform the other, especially in hybrid IoT scenarios where some devices belong to "silos" (e.g., a smart factory) and others are truly cross-device (e.g., individual smart home gadgets).
3. Reinforcement Learning in FL (Federated Reinforcement Learning - FRL)
FL can be applied to train Reinforcement Learning (RL) agents distributed across edge devices. Imagine a fleet of autonomous drones learning optimal navigation strategies collaboratively, or smart traffic lights optimizing flow across a city. Each agent learns from its local interactions with the environment, and their collective experiences are aggregated to improve a shared policy. This is crucial for scenarios where centralized RL training is impractical due to data volume, privacy, or real-time requirements.
4. Continual Learning / Lifelong Learning at the Edge
IoT environments are dynamic. Models need to adapt to new data, new tasks, and changing conditions over time without "catastrophic forgetting" of previously learned knowledge. FL, combined with continual learning techniques, can enable edge devices to maintain up-to-date models that constantly evolve, reducing the need for periodic retraining from scratch.
5. TinyML + FL
Pushing the boundaries of FL to even more constrained microcontrollers (TinyML devices) is an exciting frontier. This involves extreme quantization, highly optimized model architectures, and novel communication protocols to enable collaborative learning on devices with kilobytes of RAM and milliwatts of power consumption.
Practical Insights for AI Practitioners and Enthusiasts
For those looking to dive into this transformative field, here are some practical steps:
-
Framework Exploration: Get hands-on with dedicated FL frameworks.
- TensorFlow Federated (TFF): A powerful open-source framework from Google, designed for research and production-scale FL. It provides a flexible API for expressing FL algorithms.
- PyTorch Distributed: While not exclusively for FL, PyTorch's distributed capabilities can be adapted for FL, especially for cross-silo scenarios.
- Flower: A framework that focuses on simplicity and flexibility, allowing researchers to implement and experiment with various FL algorithms easily.
- FedML: A comprehensive open-source library that supports various FL algorithms, architectures, and deployment scenarios (cross-device, cross-silo).
- LEAF: A benchmark for FL research, providing datasets and reference implementations for various FL tasks.
-
Simulation Tools: Before deploying on real hardware, simulate different FL scenarios. Frameworks like Flower, FedML, and LEAF offer simulation capabilities to test algorithms under varying conditions (e.g., device heterogeneity, network latency, data non-IIDness).
-
Dataset Challenges: Work with real-world, non-IID IoT datasets. Public datasets like CIFAR-10 or MNIST are often used for initial FL research, but they don't fully capture the complexity of IoT data. Explore datasets from sensor networks, health monitoring, or industrial logs, and consider how to simulate non-IID distributions.
-
Hardware Considerations: Understand the impact of specialized hardware. If you have access to devices with NPUs or TPUs, experiment with how they accelerate on-device training and inference. Consider the power consumption implications of different model sizes and training frequencies.
-
Ethical Implications: Engage with the ethical considerations. While FL enhances privacy, it's crucial to discuss the trade-offs between privacy guarantees (e.g., DP budget), model accuracy, and fairness, especially in sensitive applications like healthcare or surveillance.
Conclusion
Federated Learning for resource-constrained IoT edge devices is not just a technological niche; it's a fundamental shift in how we conceive and deploy AI. It represents a powerful convergence of IoT, Edge Computing, AI, and Privacy, poised to unlock unprecedented intelligence at the very edge of our networks. The challenges are significant, ranging from managing device heterogeneity and non-IID data to ensuring robust security and efficient communication. However, the rapidly evolving landscape of solutions – from advanced aggregation algorithms and personalized FL to hierarchical architectures and cryptographic privacy enhancements – demonstrates the immense potential and ongoing innovation in this field.
For AI practitioners and enthusiasts, understanding and contributing to Federated Learning is becoming increasingly vital. It's a field rich with theoretical research questions and immediate practical applications, promising to shape the future of intelligent, privacy-preserving, and distributed AI across our interconnected world. The journey to truly intelligent, autonomous, and secure IoT ecosystems will undoubtedly be paved with the principles and innovations of Federated Learning.