Self-Healing & Adaptive Agentic SDLC: AI Agents Revolutionize Software Maintenance
Explore the future of software development with Agentic SDLC, where AI agents autonomously detect, diagnose, and remediate system issues. This paradigm shift moves beyond human-centric maintenance to self-evolving systems, promising minimal human intervention in complex architectures.
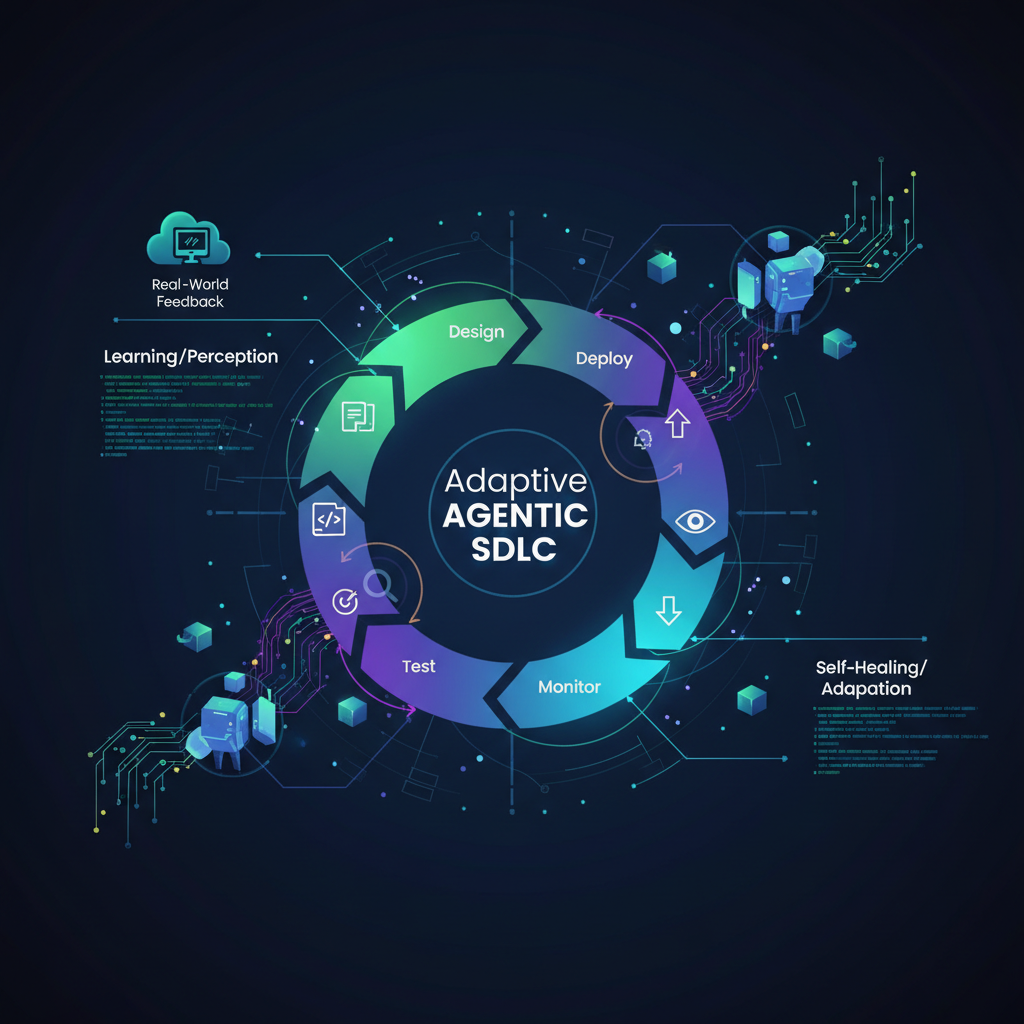
The software development lifecycle (SDLC) has long been a human-centric endeavor, relying on skilled engineers to design, code, test, deploy, and, crucially, maintain systems. While automation has steadily permeated various stages, the operational phase – particularly incident response and system maintenance – remains largely reactive and human-intensive. This status quo is increasingly unsustainable in an era of hyper-distributed, complex, and dynamic software architectures. Enter the next frontier of Agentic SDLC: Self-Healing and Adaptive Agentic SDLC, where AI agents move beyond mere code generation to autonomously detect, diagnose, and remediate issues in software systems.
This isn't just an incremental improvement; it's a paradigm shift. We're moving from systems that assist humans in maintenance to systems that can maintain and evolve themselves with minimal human intervention. This vision, once confined to science fiction, is rapidly becoming a tangible reality thanks to breakthroughs in AI.
The Unavoidable Truth: Operational Debt and the Need for Autonomy
Modern software systems are a marvel of engineering, yet their complexity is a double-edged sword. Microservices, cloud-native architectures, serverless functions, and continuous deployment pipelines introduce an unprecedented level of dynamism and interconnectedness. While these innovations accelerate development, they also amplify the challenges of operations. Bugs, performance degradations, security vulnerabilities, and infrastructure failures are not just possibilities; they are inevitabilities.
Traditionally, addressing these operational issues involves a laborious, multi-step process:
- Monitoring & Alerting: Humans configure dashboards and alerts, often leading to alert fatigue.
- Diagnosis: Engineers sift through logs, metrics, and traces, often across disparate systems, to pinpoint the root cause. This can be a time-consuming "needle in a haystack" problem.
- Remediation: Once the cause is found, engineers manually apply fixes, roll back deployments, adjust configurations, or scale resources.
- Verification: The fix is then monitored to ensure it worked and didn't introduce new problems.
This human-driven approach is slow, error-prone, and scales poorly. The cost of downtime, the burden on on-call teams, and the inevitable operational debt accumulate rapidly. Self-healing and adaptive agentic systems offer a compelling alternative, promising to drastically reduce Mean Time To Resolution (MTTR), improve system reliability, and free human engineers to focus on innovation rather than firefighting.
Why Now? The Confluence of AI Advances
The timing for this revolution is no accident. Several recent advancements in artificial intelligence have converged to make autonomous self-healing a practical reality:
- Large Language Models (LLMs): The phenomenal capabilities of LLMs in understanding natural language, generating code, performing complex reasoning, and synthesizing information from vast datasets are central. They can interpret log messages, generate diagnostic queries, propose code fixes, and even explain their reasoning.
- Multi-Agent Systems: The ability to orchestrate multiple specialized AI agents, each with a distinct role (e.g., one for monitoring, one for diagnosis, one for remediation), allows for robust, collaborative problem-solving. This mirrors how human teams tackle incidents but at machine speed.
- Reinforcement Learning (RL) / Active Learning: Agents can learn from their experiences. By observing the outcomes of various remediation attempts, they can refine their strategies, adapt to new failure modes, and optimize their performance over time. This continuous learning loop is critical for true adaptiveness.
- Advanced Observability Tools & APIs: Modern observability platforms provide the rich, granular data streams (logs, metrics, traces, events) that AI agents need to perceive the system's state accurately. These platforms offer programmatic access, enabling agents to query and interact with the system's "senses."
This synergy of capabilities is propelling AIOps beyond mere anomaly detection and alerting into the realm of autonomous action and continuous learning, embedding intelligence directly into the operational loop of the SDLC.
The Anatomy of a Self-Healing Agentic System
A self-healing agentic system can be conceptualized as a sophisticated orchestration of specialized AI agents, each contributing to the overall goal of maintaining system health. Let's break down their key components and recent developments.
1. Perception & Anomaly Detection: The Observability Agents
At the forefront are the Observability Agents, acting as the system's eyes and ears. Their role is to continuously monitor every facet of the software stack – from application code and infrastructure to network traffic and user interactions. They are designed to detect deviations from normal behavior, signaling potential issues.
Recent Developments:
- LLM-powered Log Anomaly Detection: Traditional log analysis often relies on keyword matching or statistical thresholds. LLMs elevate this by understanding the semantic meaning of log messages. An LLM can identify unusual sequences of events, correlate seemingly disparate log entries across microservices (e.g., a "database connection refused" in one service followed by "payment failed" in another), and even infer the intent behind error messages, which might indicate a novel failure mode.
- Example: An LLM agent trained on application logs might flag a series of
WARNmessages about "low disk space" on a specific pod, followed byERRORmessages about "failed to write to temporary file," even if no explicit "disk full" alert was configured. It understands the progression and correlation.
- Example: An LLM agent trained on application logs might flag a series of
- Graph Neural Networks (GNNs) for Dependency Mapping: In complex microservices architectures, a failure in one service can cascade through many others. GNNs are particularly adept at modeling these intricate dependencies. An Observability Agent leveraging GNNs can identify the blast radius of an anomaly, pinpointing the originating service and predicting downstream impacts, rather than just reporting isolated errors.
- Example: A GNN agent could detect an unusual latency spike in Service A, and immediately identify that Service B and Service C, which depend on Service A, are also starting to show degraded performance, even before their individual thresholds are breached.
- Predictive Analytics with Time-Series Models: Moving beyond reactive detection, these agents use advanced time-series forecasting models (e.g., ARIMA, Prophet, or deep learning models like LSTMs) to predict potential failures before they manifest. By analyzing historical performance data and current trends, they can anticipate resource exhaustion, impending service degradation, or even security breaches.
- Example: An agent might predict that a database's connection pool will be exhausted within the next 30 minutes based on the current rate of connection requests and historical patterns, triggering an early warning.
2. Diagnosis & Root Cause Analysis: The Diagnostic Agents
Once an anomaly is detected, the Diagnostic Agents spring into action. Their mission is to swiftly and accurately pinpoint the root cause of the problem, often under pressure. This is where the reasoning capabilities of AI truly shine.
Recent Developments:
- LLM-driven Causal Reasoning: This is a game-changer. Diagnostic agents can use LLMs to "reason" about the system. Given a set of symptoms (e.g., "high latency on API endpoint
/checkout," "database connection errors," "increased CPU usage on payment service"), the LLM can:- Formulate Hypotheses: "Could it be a database bottleneck? A recent code deployment? An external service outage?"
- Query Monitoring Systems: Based on hypotheses, it can generate specific queries to observability platforms (e.g., "Show me database query times for the last 10 minutes," "Fetch recent deployments to the payment service," "Check status of third-party payment gateway API").
- Analyze Evidence: It then synthesizes the results from these queries, analyzes call stacks, error messages, and configuration changes to confirm or refute hypotheses, ultimately identifying the most probable root cause.
- Example: An LLM agent detects a sudden spike in 5xx errors from the
OrderProcessingservice. It queries logs forOrderProcessingand finds "Connection timed out toInventoryService." It then queriesInventoryServicelogs and finds "Disk full error on/var/log." The LLM correlates these, identifies the disk full onInventoryServiceas the root cause, and notes the cascading effect.
- Knowledge Graph Integration: Diagnostic agents can integrate with enterprise knowledge graphs that map system components, dependencies, known issues, past incidents, architectural diagrams, and even runbooks. This allows them to quickly connect observed symptoms to known solutions or similar past problems, significantly accelerating diagnosis.
- Example: If a diagnostic agent identifies a specific error code, it can query a knowledge graph to see if that error code has been linked to a specific configuration bug in a previous incident, suggesting a potential fix immediately.
- Automated Experimentation (Controlled Probing): In advanced scenarios, agents might be empowered to run non-disruptive diagnostic tests or probes in a controlled environment (e.g., a canary deployment or a staging environment) to confirm a hypothesis without impacting production.
- Example: If an agent suspects a memory leak, it might spin up a temporary instance of the problematic service, run a load test, and monitor memory usage to confirm the leak before suggesting a remediation.
3. Remediation & Healing: The Remediation Agents
Once the root cause is identified, the Remediation Agents take action. This is where the "healing" aspect comes into play, executing actions to resolve the issue autonomously.
Recent Developments:
- Automated Rollbacks: This is a relatively mature practice, but agentic systems can make it smarter. An agent can initiate a rollback of a recent deployment or configuration change if it's identified as the root cause, but also intelligently assess which specific components need rolling back, rather than a blanket rollback.
- Resource Scaling & Configuration Adjustment: Agents can dynamically adjust cloud resources (e.g., scale up a struggling service, add more database connections, increase message queue capacity) or modify configuration parameters (e.g., cache invalidation, feature flag toggles) based on diagnostic findings.
- Example: If a diagnostic agent identifies a database bottleneck due to high read load, a remediation agent could automatically provision read replicas or adjust database connection pool sizes.
- Code Patching/Generation (The Holy Grail): This is where the "agentic" part truly shines. LLMs can propose and even generate small, targeted code fixes, configuration changes, or database queries to address a specific problem. This is typically done for well-understood, localized issues.
- Example: If a diagnostic agent identifies a null pointer exception in a specific function due to an unhandled edge case, an LLM could generate a
if (variable == null) { return defaultValue; }patch, test it in a sandbox, and propose its deployment.
- Example: If a diagnostic agent identifies a null pointer exception in a specific function due to an unhandled edge case, an LLM could generate a
- Automated Incident Playbooks with LLM Adaptation: While predefined playbooks exist, LLMs can adapt them. An agent can execute a playbook (e.g., "restart service," "clear cache"), but if a step fails or the context changes, the LLM can dynamically adjust the next steps, making the playbook more resilient and intelligent.
- Security Patching & Configuration Hardening: Agents can identify known vulnerabilities (e.g., from CVE databases or security scans) in deployed components and automatically apply patches or reconfigure systems to mitigate risks, often before human security teams are even aware.
4. Verification & Learning: The Testing/Feedback Agents
The final, crucial stage involves verifying the fix and ensuring continuous improvement. Testing/Feedback Agents close the loop, making the system truly adaptive.
Recent Developments:
- Automated Post-Mortem Generation: After an incident is resolved, LLMs can synthesize all the data – detection alerts, diagnostic findings, remediation actions, and their outcomes – to generate a comprehensive post-mortem report. This report can include root cause analysis, timeline of events, lessons learned, and recommendations for preventing recurrence.
- Example: An LLM agent generates a summary: "Incident: High latency on
/api/v1/users. Root Cause: Database connection pool exhaustion onUserDBdue to unoptimized querySELECT * FROM users WHERE last_login < '2023-01-01'. Remediation: Increasedmax_connectionstoUserDB, optimized query. Outcome: Latency returned to normal. Lessons Learned: Implement query monitoring forUserDB."
- Example: An LLM agent generates a summary: "Incident: High latency on
- Test Case Generation: To prevent recurrence, agents can automatically generate new unit, integration, or performance tests that specifically target the identified bug or vulnerability. These tests are then integrated into the CI/CD pipeline.
- Example: Following the database connection exhaustion incident, an agent could generate a stress test that simulates a high volume of unoptimized queries to ensure the
UserDBcan handle the load with the new configuration.
- Example: Following the database connection exhaustion incident, an agent could generate a stress test that simulates a high volume of unoptimized queries to ensure the
- Reinforcement Learning for Strategy Optimization: This is the core of adaptiveness. RL agents learn which remediation strategies are most effective for different types of failures. Over time, they build a policy that maps observed symptoms to optimal actions, continuously improving their MTTR and success rate.
- Example: An RL agent learns that for "high CPU on service X," restarting the service is often less effective than scaling up its instances, and prioritizes the latter in future similar incidents.
- Human-in-the-Loop Feedback: While the goal is autonomy, human oversight is vital, especially in early stages. Agents provide clear interfaces for human operators to review, approve, or override proposed actions. Crucially, agents learn from these human corrections, refining their internal models and decision-making processes. This builds trust and ensures safety.*
Practical Applications and the Future Outlook
The implications of self-healing and adaptive agentic SDLC are profound, offering tangible benefits across the board:
- Drastically Reduced MTTR: Incidents that once took hours or days to resolve can be mitigated in minutes or even seconds.
- Improved System Reliability and Uptime: Proactive detection and rapid, autonomous remediation lead to significantly fewer service disruptions and higher availability.
- Reduced Operational Costs: Less manual intervention means fewer on-call rotations, reduced burnout, and the ability for engineers to focus on higher-value tasks.
- Enhanced Developer Productivity: Developers can concentrate on building new features and improving existing ones, rather than constantly being pulled into incident response.
- Proactive Security Posture: Agents can identify and patch vulnerabilities, enforce security policies, and respond to threats automatically, strengthening the system's defenses.
- Autonomous System Evolution: The long-term vision extends beyond healing to evolution. Imagine systems that not only fix themselves but also adapt their architecture, optimize their code, and even refactor components based on performance data, security requirements, and evolving user needs – all driven by intelligent agents.
Challenges remain significant: Trust in autonomous systems, ensuring explainability of agent decisions, guaranteeing safety (e.g., preventing an agent from making things worse), and the inherent complexity of integrating diverse AI models with existing, often heterogeneous, infrastructure are hurdles. Ethical considerations, such as accountability for agent actions, also need careful thought.
However, the rapid pace of innovation in LLMs, multi-agent architectures, and reinforcement learning is making these challenges increasingly tractable. We are witnessing the dawn of a new era in software engineering, where AI agents are not just tools, but integral, intelligent partners in the continuous development and operation of resilient, adaptive software systems. The self-healing system is no longer a distant dream; it's the inevitable next step in the evolution of SDLC.