Self-Healing AI: Revolutionizing Software Resilience & Autonomous SDLC
Explore how AI is moving beyond code generation to create truly resilient software systems. Discover the rise of self-healing and adaptive AI agents for Autonomous SDLC, ushering in an era of robust, self-maintaining software.
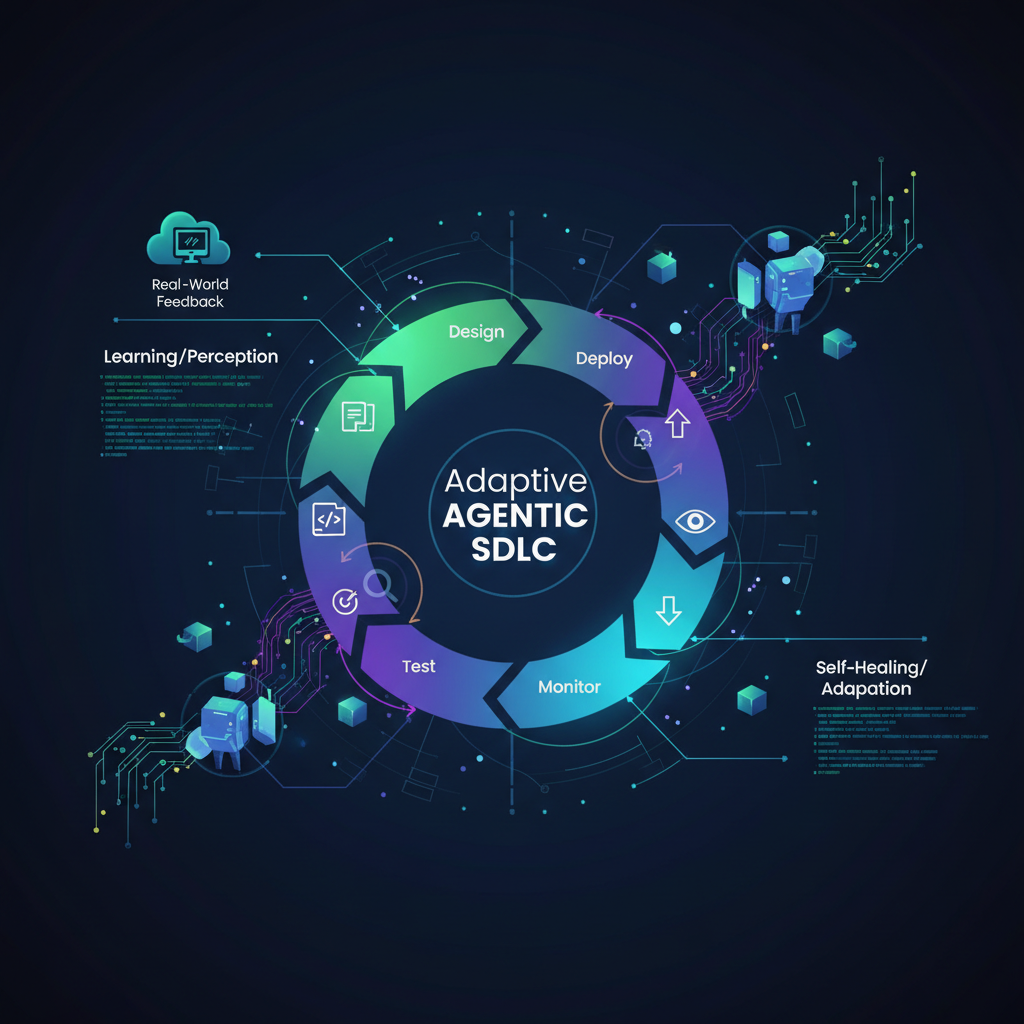
The promise of Artificial Intelligence in software development has long captivated our imaginations. Initially, much of the excitement centered on AI's ability to automate mundane tasks: generating boilerplate code, writing unit tests, or even crafting documentation. While these advancements are significant, they represent only the tip of the iceberg. The true revolution lies in moving beyond initial creation to the continuous maintenance, evolution, and, critically, the resilience of software systems. This is where the concept of self-healing and adaptive AI agents for Autonomous SDLC takes center stage, pushing the boundaries of what's possible and ushering in an era of truly resilient software.
The Imperative for Self-Healing: Beyond Code Generation
AI-generated code, while powerful and rapidly improving, often comes with its own set of challenges. It can be brittle, prone to subtle bugs in edge cases, or lack the robustness required for production systems. The traditional SDLC model, which relies heavily on human intervention for debugging, patching, and evolving systems, struggles to keep pace with the velocity of AI-driven development and the complexity of modern distributed architectures.
This is precisely why self-healing agents are not just a luxury but a necessity. They address the inherent fragility of rapidly developed systems by proactively identifying, diagnosing, and fixing issues. Imagine a software system that not only builds itself but also continuously monitors its own health, detects anomalies, and autonomously implements corrective actions—from patching a critical vulnerability to optimizing a database query or even rolling back a problematic deployment. This moves us closer to the vision of truly autonomous software engineering, where systems are not just built, but maintained and evolved with minimal human oversight.
This paradigm shift leverages advanced AI capabilities to create systems that learn from their environment, adapt to changing conditions, and recover from failures without human intervention. The economic and practical implications are profound: reduced downtime, lower maintenance costs, faster iteration cycles, and significantly improved system reliability.
Defining "Self-Healing" in the SDLC Context
At its core, "self-healing" in SDLC refers to the ability of a software system, augmented by AI agents, to detect and resolve issues autonomously, thereby restoring its intended functionality or optimizing its performance. This goes beyond simple error handling; it implies a deeper understanding of system state, root causes, and potential remedies.
What constitutes a "healing" action can vary widely:
- Code Patching: Generating and applying a small code fix (e.g., correcting a null pointer exception, fixing an off-by-one error).
- Configuration Change: Adjusting a parameter in a configuration file, updating a feature flag, or modifying resource allocation.
- Rollback: Reverting to a previous stable version of code or configuration.
- Resource Scaling: Automatically scaling up/down compute resources in response to load or performance issues.
- Test Generation for Reproduction: Creating new test cases to reliably reproduce a detected bug, aiding in diagnosis and verification.
- Dependency Management: Updating or downgrading library versions to resolve conflicts or security vulnerabilities.
It's crucial to distinguish between different modes of self-healing:
- Reactive (Post-Failure) Self-Healing: This is the most common form, where agents respond to an already observed failure or incident. For example, detecting a service outage and automatically restarting the service or initiating a rollback.
- Proactive (Predictive) Self-Healing: This involves anticipating potential failures before they occur. Agents might identify performance bottlenecks that could lead to an outage, detect configuration drift that might cause instability, or flag security vulnerabilities before they are exploited, then take preventative measures.
The level of autonomy is also a critical dimension:
- Human-in-the-Loop: Agents propose fixes or actions, but a human must approve them before execution. This is often the starting point for critical systems.
- Fully Autonomous: Agents detect, diagnose, plan, and execute fixes without any human intervention, typically within well-defined, low-risk boundaries.
Architectures for Autonomous Self-Healing Agents
Building self-healing capabilities requires a sophisticated architecture, often drawing inspiration from control theory and distributed systems. The Observe-Orient-Decide-Act (OODA) Loop, originally from military strategy, provides an excellent framework:
- Observe: Agents continuously gather data about the system's state. This includes logs, metrics (CPU, memory, latency, error rates), traces, network traffic, and even code changes.
- Orient: The observed data is processed and contextualized. This involves filtering noise, correlating events, and building a comprehensive understanding of the system's current health and potential issues.
- Decide: Based on the oriented understanding, agents determine the root cause of an issue, evaluate possible solutions, and formulate a plan of action.
- Act: The chosen corrective action is executed. This could be applying a code patch, adjusting a configuration, or initiating a rollback.
A single monolithic agent would struggle with the complexity of modern systems. Instead, Multi-Agent Systems are emerging as the preferred architecture. Here, specialized agents collaborate:
- Monitoring Agents: Continuously collect telemetry data (e.g., Prometheus exporters, ELK stack integrations).
- Diagnostic Agents: Analyze observed data, perform anomaly detection, and pinpoint root causes (e.g., using LLMs to parse logs, ML models for time-series analysis).
- Repair Agents: Generate and apply fixes (e.g., LLMs for code generation, Automated Program Repair tools).
- Test Agents: Verify the efficacy and safety of proposed fixes (e.g., generating new unit/integration tests, running existing test suites).
- Orchestration Agents: Coordinate the activities of other agents, manage workflows, and ensure overall system stability.
Crucially, these agents must integrate seamlessly with existing toolchains:
- CI/CD Pipelines: For deploying fixes, triggering tests, and managing rollbacks.
- Monitoring Systems: (e.g., Prometheus, Grafana, Datadog) as primary data sources.
- Incident Management Platforms: (e.g., PagerDuty, Opsgenie) for alerting humans when autonomous fixes fail or require oversight.
- Version Control Systems (Git): For committing code changes, tracking history, and enabling rollbacks.
- Cloud Provider APIs: For dynamic resource management (scaling, provisioning).
Core AI Technologies and Techniques
The backbone of self-healing agents relies on a sophisticated blend of AI techniques:
-
Anomaly Detection & Root Cause Analysis:
- Machine Learning Models: Time-series analysis (e.g., ARIMA, Prophet, LSTMs) to detect deviations from normal behavior in metrics. Graph Neural Networks (GNNs) can model dependencies between services to identify cascading failures or pinpoint the origin of an issue in complex microservice architectures.
- Large Language Models (LLMs): Increasingly used to parse unstructured data like logs and error messages, extract relevant information, and even summarize potential root causes. Their ability to understand context and natural language makes them invaluable for making sense of human-readable diagnostic output.
-
Automated Program Repair (APR):
- Search-Based APR: Explores a search space of possible code transformations (e.g., statement deletion, insertion, replacement) to find a patch that fixes the bug and passes relevant tests. Examples include GenProg and Angelic Fixes.
- Learning-Based APR: Trains models on large datasets of bugs and their corresponding fixes to learn patterns and generate new patches. Deep learning models can learn to generate code diffs.
- LLM-Driven Repair: LLMs like GPT-4 or Claude, given an error message, stack trace, and relevant code, can generate plausible code patches. Their strength lies in understanding the semantic context and generating human-like code. This is rapidly becoming a dominant approach.
-
Adaptive Strategies:
- Reinforcement Learning (RL): Agents can use RL to learn optimal repair policies. For instance, an agent might learn that for a specific type of database connection error, a restart is more effective than a configuration tweak, or that for a particular performance bottleneck, scaling up is better than a code optimization. The agent receives rewards for successful repairs and penalties for failed or detrimental actions, iteratively improving its decision-making.
- Meta-Learning: Learning to learn. Agents can learn how to adapt their repair strategies more quickly to new, unseen types of failures by leveraging experience from similar past incidents.
-
Contextual Understanding with LLMs:
- LLMs are pivotal for understanding the broader context of an issue. They can ingest error messages, stack traces, internal documentation, API specifications, and existing codebase to generate more accurate and effective fixes. For example, an LLM could analyze a
NullPointerException, cross-reference it with documentation about a specific library, and suggest a correct null-check or initialization pattern.
- LLMs are pivotal for understanding the broader context of an issue. They can ingest error messages, stack traces, internal documentation, API specifications, and existing codebase to generate more accurate and effective fixes. For example, an LLM could analyze a
-
Verification & Validation of Fixes:
- Automated Test Generation: Before applying a fix, agents can generate new unit or integration tests specifically designed to reproduce the original bug and then verify that the fix resolves it without introducing regressions. Property-based testing can also be employed.
- Formal Verification: For critical components, formal methods can mathematically prove the correctness of a generated patch, though this is often computationally intensive.
- Canary Deployments/A/B Testing: For production fixes, a common strategy is to deploy the fix to a small subset of users or servers (canary) and monitor its performance and stability before a full rollout. Agents can automate this process and roll back if issues arise.
- Sandbox Environments: Testing fixes in isolated, production-like environments to ensure safety and effectiveness.
Practical Applications and Use Cases
The potential applications of self-healing and adaptive AI agents span the entire software lifecycle and promise significant operational improvements:
- Automated Bug Fixing:
- Runtime Errors: Automatically detecting and patching common errors like null pointer exceptions, resource leaks, division by zero, or off-by-one errors in loops.
- API Contract Violations: Identifying when a service is returning data that violates its API contract and automatically adjusting the calling code or the service itself.
- Performance Optimization:
- Bottleneck Detection: Identifying slow database queries, inefficient algorithms, or suboptimal resource utilization.
- Automated Tuning: Applying configuration changes (e.g., database connection pool size, JVM heap settings) or even suggesting/implementing minor code refactorings to improve performance.
- Security Vulnerability Patching:
- CVE Remediation: Automatically detecting known vulnerabilities (CVEs) in dependencies or custom code and applying patches, updating libraries, or suggesting code changes to mitigate risks.
- Configuration Security: Identifying misconfigurations that expose systems to attack and automatically correcting them.
- Configuration Drift Remediation:
- Monitoring infrastructure and application configurations (e.g., Kubernetes manifests, Terraform states) and automatically reverting unauthorized changes or correcting deviations from desired state.
- Resilience Engineering:
- Proactive Chaos Engineering: Agents can autonomously introduce controlled failures (e.g., network latency, service shutdowns) into non-production environments to identify weaknesses, then generate and apply fixes for the vulnerabilities discovered.
- Self-Healing Microservices: Individual microservices can detect their own degradation, isolate themselves, and initiate self-repair or replacement processes.
- Adaptive Resource Management:
- Dynamically adjusting cloud resources (VMs, containers, serverless functions) based on observed load, performance metrics, and predicted demand, ensuring optimal cost and performance.
Challenges and Ethical Considerations
While the vision is compelling, realizing truly autonomous self-healing systems presents significant challenges:
- Trust and Explainability: How can we trust an AI agent to modify production code or critical infrastructure? Its decisions must be explainable, auditable, and transparent. Black-box decision-making is unacceptable in high-stakes environments. This requires robust logging, clear rationales for actions, and human-readable summaries of interventions.
- Safety and Rollback Mechanisms: The potential for an autonomous agent to introduce catastrophic self-inflicted wounds is a major concern. Robust safeguards are paramount, including:
- Strict Guardrails: Defining clear boundaries and constraints for agent actions.
- Automated Rollback: Ensuring that any deployed fix can be instantly and reliably reverted if it causes new issues.
- Circuit Breakers: Mechanisms to halt autonomous actions if they exceed predefined error thresholds.
- Complexity and State Explosion: Modern software systems are incredibly complex, with vast state spaces. Managing this complexity and ensuring agents can reason effectively across distributed components is a monumental task.
- Learning from Limited Data: Many novel bugs or failures may not have extensive historical data for agents to learn from. Agents need to be capable of "few-shot" or "zero-shot" learning, leveraging general knowledge and contextual understanding (often via LLMs) to address unprecedented issues.
- Human Oversight and Intervention: Defining the appropriate level of human involvement is crucial. Fully autonomous systems might be suitable for low-risk, well-understood issues, but critical or novel problems will always require human review and approval. The goal is augmentation, not replacement.
- Ethical Implications: Who is responsible when an autonomous agent makes a mistake that leads to financial loss or system failure? How do we ensure fairness and prevent bias in automated decision-making, especially when agents learn from historical data that might contain biases? These questions require careful consideration and robust governance frameworks.
Conclusion: The Future is Resilient
The journey towards self-healing and adaptive AI agents for autonomous SDLC represents a pivotal shift in how we conceive, build, and maintain software. It moves us beyond mere automation to a future where software systems possess an inherent capacity for resilience, learning, and evolution. This isn't just about making developers' lives easier; it's about building a more robust and reliable digital infrastructure for the world.
For AI practitioners and enthusiasts, this field offers a rich tapestry of cutting-edge research, practical applications, and profound challenges. It demands interdisciplinary skills—a blend of AI, software engineering, DevOps, and reliability engineering. As we continue to push the boundaries, we are not just creating smarter tools; we are envisioning a future where software systems are not merely built, but truly alive, capable of adapting, healing, and thriving in an ever-changing technological landscape. The era of resilient, self-managing software is not just coming; it's already beginning to unfold.