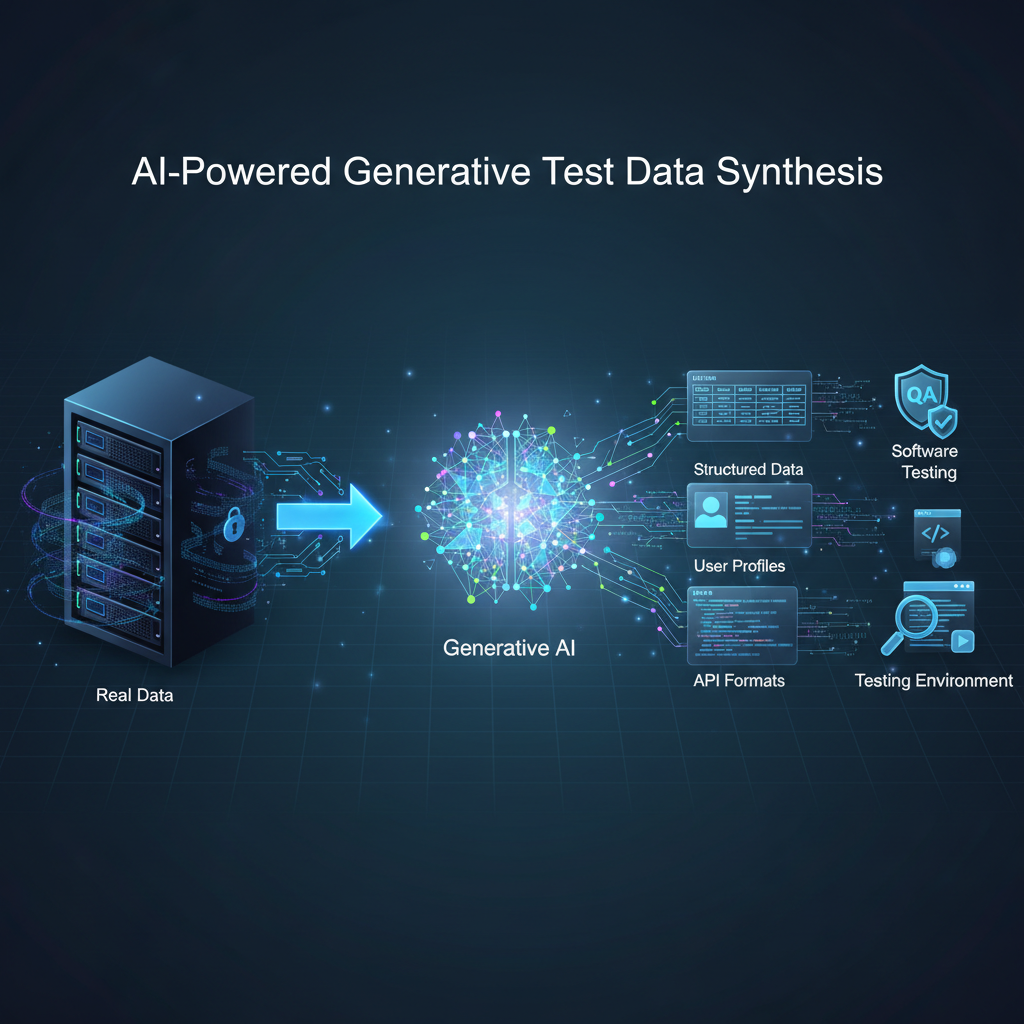
AI-Powered Generative Test Data Synthesis: Revolutionizing QA & Software Testing
Discover how AI-Powered Generative Test Data Synthesis (GTDS) is transforming Quality Assurance. This revolutionary approach uses Generative AI to create diverse, realistic, and sufficient synthetic test data, overcoming the limitations of manual and anonymized methods.
The digital landscape is evolving at an unprecedented pace, demanding software and systems that are not only feature-rich but also impeccably robust and secure. At the heart of delivering such quality lies rigorous Quality Assurance (QA) and Quality Control (QC). Yet, a persistent bottleneck has plagued these efforts for decades: the creation of diverse, realistic, and sufficient test data. Manual data generation is tedious, error-prone, and often fails to cover the myriad of scenarios encountered in real-world use. Anonymized production data, while useful, often lacks the specific edge cases needed for thorough testing and comes with significant privacy and compliance hurdles.
Enter AI-Powered Generative Test Data Synthesis (GTDS) – a revolutionary approach that leverages the cutting-edge capabilities of Artificial Intelligence, particularly Generative AI, to automatically create synthetic test data. This isn't just about populating databases; it's about intelligently crafting data that mirrors real-world complexity, uncovers hidden defects, and accelerates the entire development lifecycle. As AI models become increasingly sophisticated, GTDS is rapidly transforming from a theoretical concept into an indispensable tool for modern QA and QC automation.
What is Generative Test Data Synthesis?
At its core, Generative Test Data Synthesis is the application of AI models to automatically produce artificial data that mimics the statistical properties, patterns, and relationships found in real-world datasets. This synthetic data can take many forms:
- Structured Data: Database records, JSON/XML payloads for APIs, CSV files, and configuration data.
- Unstructured Data: Natural language text (e.g., customer reviews, log entries, error messages), code snippets, and synthetic user stories.
- Media Data: Images (e.g., synthetic medical scans, UI screenshots), audio files (e.g., voice commands), and video.
- Complex Scenarios: Entire sequences of user interactions, financial transactions, or IoT sensor readings.
The primary goal is not just to generate any data, but to generate data that is:
- Statistically Representative: Reflecting the distributions and correlations of real data.
- Diverse: Covering a wide range of typical and atypical scenarios.
- Edge Case Rich: Specifically designed to probe boundary conditions and potential failure points.
- Privacy-Preserving: Free from sensitive real-world information, making it safe for testing in regulated environments.
By automating this process, GTDS aims to overcome the traditional challenges of test data management, enabling faster, more comprehensive, and ultimately, higher-quality software delivery.
Why Now? The Timeliness and Impact of GTDS
The rise of GTDS isn't a coincidence; it's a direct response to several converging trends and advancements in the AI and software development landscapes:
1. Addressing Data Scarcity and Privacy Concerns
In highly regulated industries like healthcare, finance, and government, access to real production data for testing is severely restricted due to stringent privacy regulations (e.g., GDPR, HIPAA, CCPA). Even when anonymized, the process is complex, costly, and can sometimes strip away the very nuances needed for effective testing. GTDS offers a powerful solution by generating synthetic data that is statistically similar to real data but contains no personally identifiable information (PII) or sensitive commercial secrets. This allows development and QA teams to work with realistic data without legal or ethical compromises.
2. The Generative AI Revolution
The exponential growth in the capabilities of Generative AI models has been the primary catalyst for GTDS.
- Large Language Models (LLMs): Models like GPT-3/4, Llama, and others have demonstrated an astonishing ability to understand context, generate coherent text, and even follow complex instructions. This makes them ideal for generating structured data based on natural language prompts or schema definitions.
- Generative Adversarial Networks (GANs): GANs have excelled at creating highly realistic synthetic images, audio, and time-series data by learning to mimic complex distributions.
- Variational Autoencoders (VAEs) and Diffusion Models: These models offer alternative, often more stable, approaches to generating high-quality, diverse data across various modalities.
These advancements mean that generating sophisticated, contextually aware, and diverse data is no longer a futuristic dream but a present-day reality.
3. Fueling Shift-Left Testing and Agile/DevOps
Modern software development emphasizes "shift-left" testing, where quality assurance activities are integrated early and continuously throughout the development lifecycle. Agile methodologies and DevOps practices demand rapid iteration and continuous integration/delivery (CI/CD). Traditional test data provisioning struggles to keep pace with these demands. GTDS allows developers and testers to generate test data on-demand, within minutes or seconds, directly from their CI/CD pipelines. This eliminates waiting times, enables early bug detection, and supports a truly continuous testing paradigm.
4. Enhancing Test Coverage and Uncovering Edge Cases
Manually creating test data for every possible scenario, especially for complex systems with numerous interdependencies, is practically impossible. Edge cases, boundary conditions, and rare but critical failure modes are often missed. AI-powered generators can systematically explore the data space, identify gaps in existing test data, and proactively generate data points that target these challenging scenarios. This leads to significantly higher test coverage, more robust applications, and a reduction in post-release defects.
5. Integration with Automated Test Case Generation
The synergy between GTDS and AI-powered test case generation is a powerful emerging trend. Imagine an AI that not only creates realistic data but also understands the application's logic sufficiently to generate the actual test steps and assertions that utilize that data. This moves towards a truly holistic AI-driven testing solution, where the entire test suite, from data to execution, is intelligently orchestrated.
6. Significant Cost and Time Savings
The manual effort involved in test data management—from data identification and extraction to anonymization, subsetting, and creation—is substantial. By automating this labor-intensive process, GTDS dramatically reduces the time and cost associated with test data provisioning, freeing up valuable human resources to focus on more complex analytical and exploratory testing tasks.
Technical Depth and Practical Applications
Understanding the underlying technologies is crucial for effectively leveraging GTDS. Different generative models excel at different types of data and use cases.
A. Core Technologies & Approaches
-
Large Language Models (LLMs)
- Mechanism: LLMs are deep learning models trained on vast amounts of text data, enabling them to understand, generate, and manipulate human language. They learn complex grammatical structures, semantic relationships, and contextual nuances.
- Application: LLMs are exceptionally versatile for generating structured data that can be described textually.
- Structured Data Generation: Generating JSON, XML, YAML, or CSV data based on a schema and natural language prompts. For instance, a prompt like "Generate 10 customer profiles with names, email addresses, and valid US phone numbers, ensuring a mix of ages (20-60), varying income levels, and at least two customers from California" can yield a perfectly formatted JSON array.
- Realistic Text Data: Creating synthetic log entries, error messages, user reviews, or even entire user stories that reflect different sentiments or scenarios.
- API Request/Response Payloads: Generating diverse API request bodies or expected response structures, including cases with missing fields, invalid data types, or boundary values, crucial for API testing.
- Example: Using OpenAI's GPT-4 API to generate a list of mock product descriptions and their corresponding SKUs for an e-commerce platform's product catalog API.
json
[ { "product_id": "PROD001", "name": "Ergonomic Office Chair", "description": "High-back mesh office chair with adjustable lumbar support and armrests. Perfect for long working hours.", "category": "Office Furniture", "price": 249.99, "in_stock": true }, { "product_id": "PROD002", "name": "Wireless Bluetooth Earbuds", "description": "Compact, noise-cancelling earbuds with 24-hour battery life and touch controls. Ideal for workouts and travel.", "category": "Electronics", "price": 79.99, "in_stock": true }, // ... 8 more similar entries ][ { "product_id": "PROD001", "name": "Ergonomic Office Chair", "description": "High-back mesh office chair with adjustable lumbar support and armrests. Perfect for long working hours.", "category": "Office Furniture", "price": 249.99, "in_stock": true }, { "product_id": "PROD002", "name": "Wireless Bluetooth Earbuds", "description": "Compact, noise-cancelling earbuds with 24-hour battery life and touch controls. Ideal for workouts and travel.", "category": "Electronics", "price": 79.99, "in_stock": true }, // ... 8 more similar entries ]
-
Generative Adversarial Networks (GANs)
- Mechanism: GANs consist of two competing neural networks: a Generator that creates synthetic data, and a Discriminator that tries to distinguish between real and generated data. Through this adversarial process, the Generator learns to produce increasingly realistic data that can fool the Discriminator.
- Application: GANs excel at generating complex, high-dimensional data where subtle patterns and correlations are critical.
- Image Generation: Creating synthetic images for visual testing (e.g., diverse UI screenshots to test visual regression, synthetic medical scans for AI model training, diverse facial images for facial recognition system robustness testing).
- Time-Series Data: Generating realistic sensor readings, financial market data (stock prices, trading volumes), or network traffic patterns to test anomaly detection systems.
- Complex Tabular Data: When correlations between columns are intricate and non-linear, GANs can generate synthetic tabular datasets that preserve these relationships better than simpler methods.
- Example: Generating synthetic credit card transaction data that includes realistic patterns of fraudulent activity, allowing an anti-fraud system to be tested against a diverse set of attack vectors without using real customer financial data. This might involve generating sequences of transactions with varying amounts, locations, and merchant categories that mimic known fraud schemes.
-
Variational Autoencoders (VAEs)
- Mechanism: VAEs are a type of generative model that learns a compressed, continuous "latent space" representation of the input data. They consist of an encoder that maps input data to this latent space and a decoder that reconstructs data from it. New data can be generated by sampling points from this latent space and passing them through the decoder.
- Application: VAEs are particularly good for generating data that maintains specific statistical properties of the original dataset, especially for tabular data or sequences where smooth transitions between data points are important. They offer more control over the generated data's properties compared to GANs.
- Example: Generating synthetic patient records for a healthcare application. A VAE can learn the distributions and correlations of various health markers (e.g., blood pressure, glucose levels, age, BMI) from a real dataset and then generate new, statistically consistent patient profiles. This ensures that the test data reflects realistic physiological ranges and interdependencies without exposing actual patient information.
-
Diffusion Models
- Mechanism: Diffusion models work by progressively adding Gaussian noise to an image (or other data) until it becomes pure noise, and then learning to reverse this process, "denoising" the data back to its original form. They have demonstrated remarkable success in generating high-quality, diverse, and realistic images.
- Application: Similar to GANs but often producing higher quality and more diverse outputs, particularly for images and audio.
- Visual Regression Testing: Generating diverse UI component states (e.g., different themes, screen sizes, data states) to thoroughly test visual consistency across application versions.
- Audio Command Generation: Creating synthetic audio commands or speech samples for voice-activated systems, covering different accents, speaking speeds, and background noise levels.
- Example: Generating a dataset of synthetic UI screenshots for an e-commerce website, showing variations in product images, text content, and layout under different conditions (e.g., empty cart, full cart, discount applied, out-of-stock items) to test the robustness of visual regression testing tools.
-
Rule-Based & Constraint-Based Generation (often integrated)
- Mechanism: While not purely "AI-powered" in the generative sense, these techniques are crucial for ensuring the validity and integrity of AI-generated data. They use predefined rules, regular expressions, data types, and business constraints (e.g., "email must be a valid format," "age must be > 18," "order total must be positive").
- Application: These systems act as a "sanity check" and a guiding framework for generative models. They define the boundaries within which the AI operates, ensuring that even highly diverse synthetic data adheres to the application's fundamental business logic and data schema. They are often used in conjunction with AI models to refine and validate the output.
B. Practical Implementation & Workflow
Integrating GTDS into a QA workflow typically follows these steps:
-
Data Schema & Constraints Definition: The first step is to clearly define the structure, data types, and business rules for the required test data. This can be done using existing artifacts like JSON Schema, OpenAPI specifications (for APIs), database schemas, or even natural language descriptions of domain-specific entities. This definition serves as the blueprint for the generative AI.
-
Model Selection & Training (if applicable):
- For LLMs: This primarily involves selecting a suitable model (e.g., GPT-4, Llama 3) and focusing on prompt engineering.
- For GANs/VAEs/Diffusion Models: If a pre-trained model isn't available for your specific data type, you might need to train a model on a small, representative, and ideally anonymized sample of real data. This training phase teaches the model the underlying patterns and distributions.
-
Prompt Engineering (for LLMs): For LLM-based generation, crafting detailed and precise prompts is key. The prompt should specify:
- The desired data format (e.g., JSON array, CSV).
- The entities and their attributes.
- The volume of data.
- Diversity requirements (e.g., "mix of ages," "varying income levels").
- Specific scenarios or edge cases (e.g., "one with a missing required field," "one with an invalid email format," "a customer with a high-value order and a history of returns").
Example Prompt:
Generate a JSON array of 5 customer profiles for an e-commerce platform. Each profile should include: - customer_id (unique string) - first_name (string) - last_name (string) - email (valid email format) - phone_number (valid US phone number format) - address (object with street, city, state, zip_code) - registration_date (ISO 8601 date, within the last 2 years) - total_orders (integer, 0 to 50) - average_order_value (float, 10.00 to 500.00) - is_premium_member (boolean) Ensure the following diversity: - At least one customer with 0 orders. - At least one customer with a very high average_order_value (>400). - At least two premium members. - Vary states across California, New York, and Texas. - Include one customer with a clearly invalid email format (e.g., missing '@').Generate a JSON array of 5 customer profiles for an e-commerce platform. Each profile should include: - customer_id (unique string) - first_name (string) - last_name (string) - email (valid email format) - phone_number (valid US phone number format) - address (object with street, city, state, zip_code) - registration_date (ISO 8601 date, within the last 2 years) - total_orders (integer, 0 to 50) - average_order_value (float, 10.00 to 500.00) - is_premium_member (boolean) Ensure the following diversity: - At least one customer with 0 orders. - At least one customer with a very high average_order_value (>400). - At least two premium members. - Vary states across California, New York, and Texas. - Include one customer with a clearly invalid email format (e.g., missing '@'). -
Data Generation & Validation: The AI model processes the input (prompt or training data) and generates the synthetic data. Crucially, this generated data then undergoes automated validation against the predefined schema and constraints. This step catches any inconsistencies or invalid data points produced by the AI, ensuring data quality.
-
Integration into Test Automation Frameworks: The validated synthetic data is then seamlessly fed into existing test automation scripts and frameworks. Whether it's UI automation tools like Selenium, Playwright, or Cypress, or API testing frameworks like Postman, RestAssured, or Karate, the generated data becomes the fuel for automated test execution.
-
Feedback Loop & Refinement: The results of the tests provide invaluable feedback. If a specific bug is uncovered, or if certain test scenarios consistently fail due to insufficient data, this information can be used to refine the data generation process. New prompts can be crafted, or models can be fine-tuned to generate more targeted data that specifically addresses the identified issues, creating a continuous improvement cycle.
Challenges & Future Directions
While GTDS offers immense promise, it's not without its challenges:
- Data Fidelity & Realism: Ensuring that synthetic data is truly representative of real-world data and doesn't introduce subtle biases or unrealistic patterns is paramount. Over-simplification or misrepresentation can lead to false positives (bugs found in synthetic data that don't exist in real data) or, worse, false negatives (real bugs missed because the synthetic data wasn't realistic enough). Robust validation metrics and human expert review are essential.
- Bias Replication: If the generative model is trained on real data that contains inherent biases (e.g., demographic biases in customer data), the synthetic data will likely replicate and potentially amplify these biases. Addressing this requires careful data preprocessing, debiasing techniques, and ethical considerations in model design.
- Complexity of Relationships: Generating data that accurately reflects complex, multi-faceted relationships between different entities (e.g., a customer's entire journey including purchase history, support tickets, loyalty status, and social media interactions) remains a significant challenge. This often requires sophisticated graph-based generative models or multi-modal approaches.
- Explainability: Understanding why a generative model produced a particular data point or pattern can be difficult, especially with black-box models like deep neural networks. This lack of explainability can hinder debugging and erode trust in the synthetic data.
- Scalability: Generating massive volumes of diverse, high-quality data efficiently and cost-effectively, especially for big data applications, requires significant computational resources and optimized generative pipelines.
- Ethical Considerations: While GTDS is a boon for privacy, the underlying generative AI technology also raises ethical questions. The potential for misuse, such as generating "deepfake" data for malicious purposes, necessitates robust ethical guidelines, responsible AI development, and regulatory frameworks.
Future directions will likely focus on:
- Hybrid Models: Combining the strengths of different generative models (e.g., LLMs for structured text, GANs for images) within a single framework.
- Domain-Specific Models: Developing specialized generative models fine-tuned for specific industries (e.g., healthcare, finance) to capture nuanced domain knowledge.
- Enhanced Control and Interpretability: Research into methods that allow greater human control over the generation process and provide better insights into why certain data is generated.
- Automated Validation and Feedback Loops: More sophisticated AI-driven validation mechanisms that can automatically assess data quality and provide actionable feedback for model refinement.
Value for AI Practitioners and Enthusiasts
For AI Practitioners:
GTDS represents a compelling, real-world application of advanced AI models. It offers significant opportunities for:
- Applied Research: Developing novel generative architectures, fine-tuning existing models for specific data types, and exploring new techniques for ensuring data fidelity and diversity.
- Engineering Challenges: Building robust pipelines for data schema definition, prompt engineering, automated validation, and seamless integration with existing CI/CD workflows.
- Data Science Expertise: A deep understanding of data distributions, statistical properties, and model evaluation metrics is crucial for assessing the quality and realism of synthetic data.
- Ethical AI Development: Engaging with the critical aspects of bias detection, debiasing, and responsible deployment of generative models in sensitive contexts.
This field provides a direct pathway to solving a critical engineering problem using state-of-the-art AI, offering tangible impact and professional growth.
For AI Enthusiasts:
GTDS offers a tangible and exciting demonstration of how generative AI extends beyond creative content generation into practical, business-critical automation. It highlights:
- The Power of Generative AI: Witnessing how models can create complex, realistic data from scratch is a powerful illustration of AI's capabilities.
- Importance of Data Quality: Understanding that the quality of AI-generated data directly impacts the quality of the software it tests.
- The Iterative Nature of AI: Recognizing that AI development is an iterative process of model selection, training, evaluation, and refinement.
- Practical Applications: Seeing how AI can directly improve software development workflows, making them faster, more efficient, and more secure.
It's an accessible entry point to explore prompt engineering, model evaluation, and the integration of AI into existing software development and testing practices.
Conclusion
AI-Powered Generative Test Data Synthesis is rapidly transitioning from a niche concept to an indispensable component of modern QA and QC automation. By intelligently addressing the perennial challenges of data scarcity, privacy, and test coverage, GTDS empowers development teams to build more robust, secure, and high-quality software at an accelerated pace. As generative AI continues its rapid evolution, we can expect GTDS to become even more sophisticated, offering unprecedented capabilities in creating hyper-realistic, context-aware, and scenario-rich test data. For anyone involved in software delivery, understanding and embracing this technology is no longer an option, but a strategic imperative. The future of quality is synthetic, and it's being built by AI.