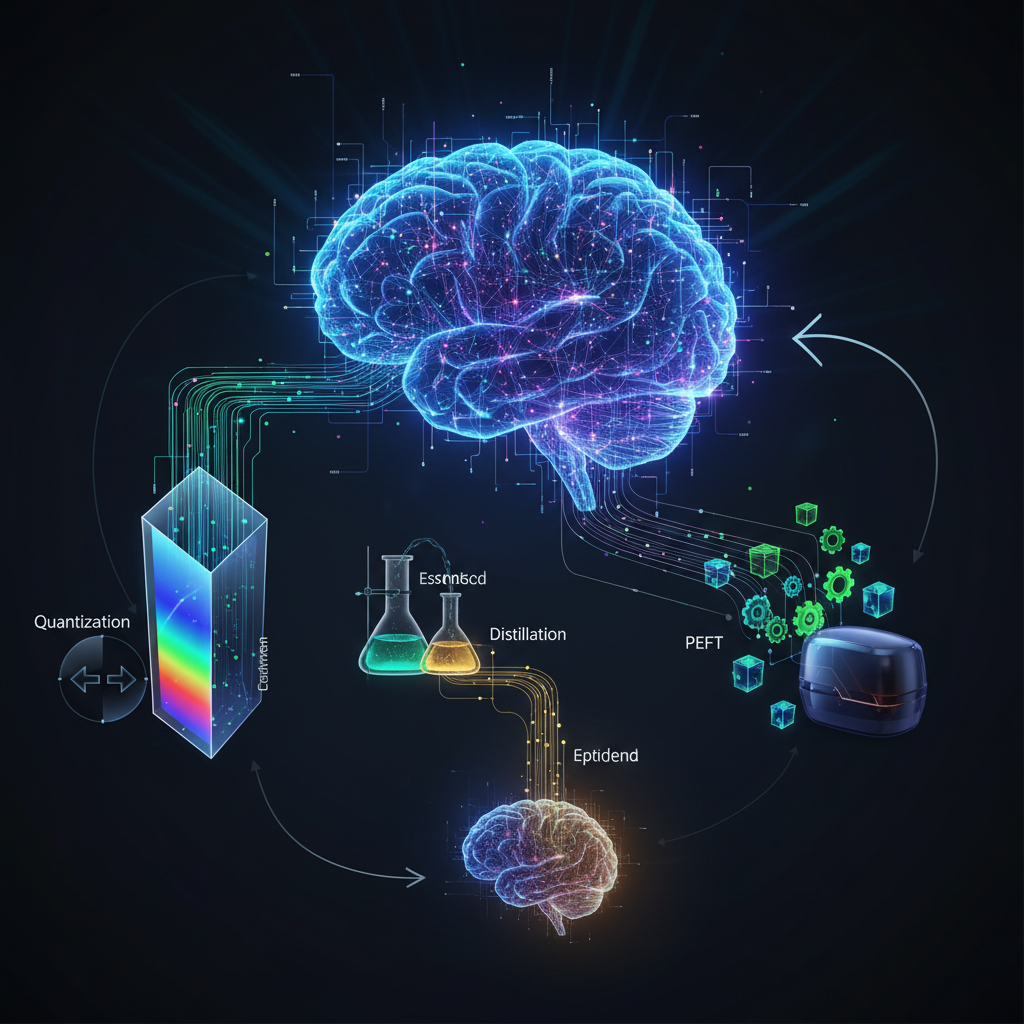
Demystifying Lean LLMs: Quantization, Distillation, and Parameter-Efficient Fine-Tuning
Large Language Models (LLMs) are powerful but resource-intensive. This post explores cutting-edge techniques like quantization, distillation, and parameter-efficient fine-tuning to make LLMs smarter, leaner, and more deployable for broader applications.
The era of Large Language Models (LLMs) has undeniably reshaped the landscape of artificial intelligence. From generating nuanced prose to performing complex reasoning, models like GPT-4, LLaMA, and Claude have demonstrated capabilities once thought to be science fiction. However, this revolution comes with a significant caveat: these models are gargantuan. Their immense computational requirements, massive parameter counts, and insatiable appetite for resources make them expensive, slow, and often inaccessible for many practical applications, especially on edge devices, with limited budgets, or for tasks demanding strict data privacy.
This challenge has spurred a critical wave of innovation aimed at democratizing LLM technology. The focus has shifted from merely building bigger models to making them smarter, leaner, and more deployable. This blog post delves into the cutting-edge techniques that are bridging this gap: quantization, distillation, and parameter-efficient fine-tuning (PEFT). Together, these methods are making LLMs practical for a broader range of use cases, from on-device AI to highly specialized industrial applications, moving them beyond hyperscale data centers and into the hands of every developer and organization.
The Imperative for Efficiency: Why Smaller, Faster LLMs Matter
Before diving into the "how," let's solidify the "why." The drive for efficient LLMs isn't just an academic pursuit; it's a practical necessity fueled by several critical factors:
- Cost Reduction: Running inference on large LLMs, especially through cloud APIs, can quickly become prohibitively expensive. Efficient models dramatically lower operational costs.
- Latency Improvement: Real-time applications like chatbots, virtual assistants, or interactive gaming demand instantaneous responses. Smaller models infer faster.
- Edge Deployment: The dream of AI running directly on smartphones, IoT devices, smart home appliances, or embedded systems requires models that fit within severe memory and computational constraints.
- Data Privacy and Security: For sensitive data (e.g., medical records, financial information), sending prompts to third-party cloud LLMs is often a non-starter. Local, on-device inference ensures data remains private and secure.
- Specialized Applications: Many industries require highly tailored language models (e.g., legal document analysis, medical diagnostics, scientific research). Training or fine-tuning massive models for niche domains is inefficient; smaller, specialized models are more agile.
- Sustainability: The energy consumption of large AI models is a growing concern. Efficient models contribute to a greener AI ecosystem by reducing carbon footprint.
- Democratization: By lowering the barriers to entry, efficient LLMs empower smaller teams, startups, and individual developers to leverage advanced AI capabilities without needing "big tech" resources.
Quantization: Shrinking Models Without Losing Their Minds
At its core, quantization is about reducing the precision of the numerical representations within a neural network. Most LLMs are trained using 32-bit floating-point numbers (FP32) for their weights and activations. Quantization converts these to lower-precision formats, such as 16-bit floats (FP16), 8-bit integers (INT8), 4-bit integers (INT4), or even binary (1-bit).
How it Works:
Imagine you have a highly detailed map. Quantization is like simplifying that map by using fewer colors or coarser lines. While you lose some minute details, the overall structure and functionality of the map remain intact. In LLMs, this means:
- Reduced Model Size: A 4-bit model is theoretically 8 times smaller than its 32-bit counterpart. This allows larger models to fit into memory-constrained devices.
- Faster Computation: Lower precision numbers require less memory bandwidth and can be processed more quickly by specialized hardware (e.g., INT8 operations are often much faster than FP32).
- Lower Power Consumption: Less data movement and simpler computations translate to reduced energy usage.
Key Techniques and Developments:
-
Post-Training Quantization (PTQ): This is the simplest approach, where a pre-trained FP32 model is converted to a lower precision after training.
- GPTQ (Generative Pre-trained Transformer Quantization): A highly effective PTQ method that quantizes models to 4-bit with minimal performance degradation. It works by quantizing weights layer by layer, minimizing the error introduced by quantization. GPTQ is widely used for running large models like LLaMA on consumer GPUs.
- AWQ (Activation-aware Weight Quantization): Recognizes that not all weights are equally important. AWQ prioritizes the quantization of weights that have a larger impact on activation output, preserving model performance by being selective about where precision is reduced.
-
Quantization-Aware Training (QAT): Here, the model is trained with the knowledge that it will eventually be quantized. This often involves simulating the quantization process during training, allowing the model to learn to be robust to precision reduction. While more complex, QAT can yield better accuracy than PTQ.
-
QLoRA (Quantized LoRA): This is a game-changer. QLoRA combines 4-bit quantization with LoRA (which we'll discuss shortly) for efficient fine-tuning. It allows developers to fine-tune massive 4-bit quantized models on consumer-grade GPUs (e.g., a 65B parameter model on a single 48GB GPU), making large-scale adaptation incredibly accessible.
Example: Running a Quantized LLaMA Model
Using libraries like bitsandbytes or AutoGPTQ with Hugging Face's transformers library, you can load and run quantized models with just a few lines of code:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load a 4-bit quantized model (e.g., from Hugging Face Hub)
# This model has been pre-quantized or uses bitsandbytes for dynamic quantization
model_id = "TheBloke/Llama-2-7B-Chat-GPTQ" # Example GPTQ quantized model
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.float16, # Use float16 for activations if possible
revision="main" # Or a specific branch if available
)
# Generate text
prompt = "Tell me a short story about a brave knight."
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
output = model.generate(input_ids, max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load a 4-bit quantized model (e.g., from Hugging Face Hub)
# This model has been pre-quantized or uses bitsandbytes for dynamic quantization
model_id = "TheBloke/Llama-2-7B-Chat-GPTQ" # Example GPTQ quantized model
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.float16, # Use float16 for activations if possible
revision="main" # Or a specific branch if available
)
# Generate text
prompt = "Tell me a short story about a brave knight."
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
output = model.generate(input_ids, max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
This simple example demonstrates how a powerful LLM, otherwise too large for many setups, can be loaded and run efficiently thanks to quantization.
Distillation: Learning from the Master
Knowledge distillation is a technique where a smaller, more efficient "student" model is trained to mimic the behavior of a larger, more complex "teacher" model. Instead of learning directly from raw data and ground truth labels, the student learns from the "soft targets" (e.g., probability distributions over classes, hidden states, attention mechanisms) produced by the teacher.
How it Works:
Think of it like an apprentice learning from a master craftsman. The apprentice doesn't just copy the final product; they observe the master's techniques, decision-making process, and subtle nuances. The student model learns the knowledge encoded in the teacher, often leading to performance surprisingly close to the teacher, despite being significantly smaller.
Key Concepts and Developments:
- Soft Targets: The teacher model's output probabilities (logits) provide more information than just the hard ground truth labels. For example, if a teacher model predicts "dog" with 90% confidence and "cat" with 9% confidence for an image, the student learns this nuanced distribution, not just "dog."
- Intermediate Representations: Sometimes, distillation involves the student mimicking the teacher's hidden layer activations or attention distributions, capturing deeper semantic knowledge.
- Architectural Flexibility: The student model can have a completely different architecture from the teacher, allowing for significant design optimizations.
Examples of Distilled Models:
- TinyLlama: A 1.1B parameter model trained on 1 trillion tokens, designed to be a compact yet capable LLM.
- Phi-3-mini (3.8B parameters), Phi-3-small (7B parameters): Microsoft's Phi models are excellent examples of smaller, highly capable models achieved through careful data curation and potentially distillation-like training processes, offering impressive performance for their size.
- Gemma-2B, Gemma-7B: Google's family of lightweight, open models, also demonstrating strong performance in a compact footprint.
These models are not just "smaller versions" but are often specifically designed and trained (or distilled) for efficiency, making them ideal for edge and specialized applications.
Distillation for RAG (Retrieval Augmented Generation):
Distillation is also proving valuable in improving the efficiency of RAG systems. A large LLM might be excellent at generating relevant responses or embeddings for retrieval. This capability can be distilled into a smaller model, which can then handle the retrieval or initial generation steps more efficiently, reducing the load on the larger, more expensive LLM.
Parameter-Efficient Fine-Tuning (PEFT): Adapting Giants with a Light Touch
Traditional fine-tuning involves updating all the parameters of a pre-trained LLM for a specific downstream task. For models with billions of parameters, this is computationally expensive, requires vast amounts of memory, and generates a new, full-sized model checkpoint for each task. Parameter-Efficient Fine-Tuning (PEFT) methods overcome these challenges by only updating a small subset of parameters or introducing a small number of new, trainable parameters.
How it Works:
Instead of repainting the entire masterpiece, PEFT methods are like adding small, specialized brushes or layers of varnish that subtly adapt the existing artwork to a new context. The vast majority of the pre-trained model's weights remain frozen, preserving its foundational knowledge while efficiently adapting it to a new domain or task.
Key Techniques and Developments:
-
LoRA (Low-Rank Adaptation): This is perhaps the most popular and impactful PEFT method. LoRA injects small, trainable rank-decomposition matrices into the transformer layers of the pre-trained model.
- For a weight matrix
W(e.g.,W_q,W_k,W_v,W_oin attention), LoRA adds a small updateΔW = BA, whereBandAare much smaller matrices (e.g.,Wmight bed x d, whileBisd x randAisr x d, withr << d). OnlyBandAare trained. - This significantly reduces the number of trainable parameters (often by 1000x or more), making fine-tuning feasible on consumer hardware and allowing for multiple task-specific LoRA adapters to be swapped in and out without reloading the entire base model.
- For a weight matrix
-
Adapter Layers: These involve inserting small, task-specific neural network modules (adapters) between existing layers of the pre-trained model. Only the parameters of these adapter layers are trained, keeping the original model weights frozen.
-
Prefix Tuning / Prompt Tuning: Instead of modifying the model's weights, these methods learn a small sequence of "virtual tokens" (a prefix or prompt) that are prepended to the input. This learned prefix guides the LLM's behavior and output for a specific task without altering its core weights.
- P-tuning v2: An advanced version of prompt tuning that shows strong performance across various tasks by introducing trainable parameters across multiple layers, offering a good balance between expressiveness and parameter efficiency.
Example: Fine-tuning with LoRA and Hugging Face PEFT Library
The Hugging Face PEFT library makes applying these techniques incredibly straightforward:
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
import torch
# 1. Load a base model (e.g., a smaller LLaMA variant)
model_id = "meta-llama/Llama-2-7b-hf" # Or a quantized version
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
# Optional: Prepare model for k-bit training (e.g., 4-bit) if using QLoRA
# model = prepare_model_for_kbit_training(model)
# 2. Define LoRA configuration
lora_config = LoraConfig(
r=8, # LoRA attention dimension
lora_alpha=16, # Alpha parameter for LoRA scaling
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # Modules to apply LoRA to
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM", # Or SEQ_CLS, TOKEN_CLS, etc.
)
# 3. Get the PEFT model
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # Shows only the LoRA parameters are trainable
# Now, you can train this 'model' with your specific dataset
# The base model weights remain frozen, only the LoRA adapters are updated.
# This requires significantly less GPU memory and time.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
import torch
# 1. Load a base model (e.g., a smaller LLaMA variant)
model_id = "meta-llama/Llama-2-7b-hf" # Or a quantized version
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
# Optional: Prepare model for k-bit training (e.g., 4-bit) if using QLoRA
# model = prepare_model_for_kbit_training(model)
# 2. Define LoRA configuration
lora_config = LoraConfig(
r=8, # LoRA attention dimension
lora_alpha=16, # Alpha parameter for LoRA scaling
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # Modules to apply LoRA to
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM", # Or SEQ_CLS, TOKEN_CLS, etc.
)
# 3. Get the PEFT model
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # Shows only the LoRA parameters are trainable
# Now, you can train this 'model' with your specific dataset
# The base model weights remain frozen, only the LoRA adapters are updated.
# This requires significantly less GPU memory and time.
Hardware and Software Co-design: The Symbiotic Relationship
The true power of these efficiency techniques is unlocked when combined with specialized hardware and optimized software frameworks.
- Hardware: Modern GPUs (especially NVIDIA's with Tensor Cores for FP16/INT8), NPUs (Neural Processing Units) in mobile devices, and custom ASICs are designed to accelerate low-precision computations.
- Software Frameworks:
- ONNX Runtime, OpenVINO: Frameworks for optimizing and deploying models across various hardware.
bitsandbytes: A Python library that provides efficient 8-bit and 4-bit quantization routines for PyTorch models, crucial for QLoRA.AutoGPTQ: A library for easy application of GPTQ quantization.- Hugging Face
PEFTlibrary: Simplifies the application of LoRA, Prefix Tuning, and other PEFT methods. llama.cpp: An incredible project that enables running LLaMA and other LLMs on commodity hardware (even CPUs) by aggressively quantizing them and optimizing inference for various architectures.
This synergy between algorithms and hardware is critical for pushing LLMs to the edge.
Practical Applications and Use Cases: Where Efficiency Shines
The accessibility enabled by quantization, distillation, and PEFT opens up a vast array of new possibilities:
-
On-Device AI:
- Smartphones & Tablets: Running local chatbots, personalized content generation, or advanced voice assistants without cloud dependency.
- Wearables & IoT: Enabling intelligent features in smartwatches, health monitors, or home automation devices where connectivity is intermittent or power is limited.
- Automotive: Local processing for in-car assistants, predictive maintenance, or advanced driver-assistance systems (ADAS).
-
Specialized Domain Experts:
- Healthcare: Deploying fine-tuned LLMs for medical transcription, diagnostic support, or patient query answering within secure hospital networks, ensuring data privacy.
- Legal: Summarizing legal documents, assisting with contract review, or answering legal questions for specific jurisdictions, running locally in law firms.
- Finance: Analyzing market data, generating financial reports, or providing personalized investment advice within secure banking systems.
-
Customer Service & Support:
- Deploying smaller, fine-tuned LLMs to handle specific FAQs, intent recognition, or initial triage, significantly reducing API costs and improving response times compared to routing every query to a large cloud LLM.
- Creating hyper-personalized customer interactions by fine-tuning models on specific customer data locally.
-
Offline Capabilities: Providing robust LLM functionality in environments with limited or no internet connectivity, such as remote field operations, military applications, or disaster relief efforts.
-
Gaming & VR/AR: Integrating dynamic NPC dialogue, procedural story generation, or intelligent virtual agents directly into games or immersive experiences, enhancing realism and interactivity without latency.
-
Industrial IoT & Edge Computing: Processing sensor data from manufacturing plants, energy grids, or agricultural sites to generate real-time insights, predict failures, or issue control commands locally, reducing reliance on cloud infrastructure and improving resilience.
-
Personalized Content Generation: Tailoring marketing copy, email drafts, or creative writing directly on a user's device, respecting user data and preferences without external data transfer.
Challenges and Future Directions
While these techniques offer immense promise, they are not without their challenges:
- Performance vs. Efficiency Trade-off: The primary challenge is always finding the optimal balance. Aggressive quantization or distillation can sometimes lead to a noticeable drop in performance for complex tasks.
- Quantization Granularity: Developing adaptive quantization schemes that can vary precision across different parts of the model (e.g., more precision for critical layers, less for others) is an active research area.
- Data Scarcity for Fine-tuning: Efficient methods for fine-tuning with very limited domain-specific data remain crucial, especially for niche applications.
- Evaluation Metrics: Developing robust and standardized metrics to compare the performance of highly quantized or distilled models against their larger counterparts, especially for subjective generative tasks, is essential.
- Tooling and Frameworks: Continued development of user-friendly, integrated tools and frameworks will be vital to simplify the application of these complex techniques for a broader audience.
- Multi-modal Efficiency: Extending these techniques to multi-modal LLMs (e.g., for image-to-text, video analysis, or audio understanding) is the next frontier, as these models are even more resource-intensive.
Conclusion
The pursuit of efficient and accessible LLMs is one of the most exciting and impactful areas in AI today. Techniques like quantization, distillation, and parameter-efficient fine-tuning are not just incremental improvements; they are foundational shifts that are democratizing access to powerful AI. They are transforming LLMs from exclusive, cloud-bound behemoths into versatile, deployable agents that can operate across a spectrum of devices and environments.
As research continues and tooling matures, we can expect to see LLMs seamlessly integrated into our daily lives, powering intelligent applications on our personal devices, securing sensitive data within organizations, and enabling a new generation of AI-driven innovation at the edge. The future of LLMs is not just about scale; it's about smart, sustainable, and ubiquitous intelligence.