RAG: The Game-Changer for Reliable LLM Applications
Retrieval-Augmented Generation (RAG) is transforming LLMs from impressive curiosities into indispensable tools. Discover how RAG addresses common LLM limitations like hallucination and outdated knowledge, providing factual grounding for robust, production-ready AI applications.
The era of Large Language Models (LLMs) has revolutionized how we interact with information, offering unprecedented capabilities in understanding, generating, and summarizing text. Yet, for all their brilliance, standalone LLMs often stumble on critical practical hurdles: they hallucinate, their knowledge is frozen at their training cut-off date, and they struggle to provide verifiable sources for their claims. Enter Retrieval-Augmented Generation (RAG) – a paradigm shift that marries the generative power of LLMs with the factual grounding of external knowledge bases. RAG isn't just an incremental improvement; it's rapidly becoming the de facto standard for building reliable, production-ready LLM applications, transforming them from impressive curiosities into indispensable tools.
The LLM Dilemma: Why RAG Became Essential
Before diving into RAG's mechanics, it's crucial to understand the fundamental limitations it addresses. Imagine asking an LLM about the latest scientific breakthroughs or your company's proprietary product specifications. Without RAG, you're likely to encounter:
- Hallucination: The LLM confidently invents facts or coherent-sounding but incorrect information. This is perhaps the most dangerous flaw for practical applications.
- Knowledge Cut-off: LLMs are trained on vast datasets up to a certain point in time. They cannot access real-time information or data that wasn't part of their training corpus, making them perpetually outdated for dynamic knowledge.
- Lack of Explainability & Attribution: When an LLM provides an answer, it's often a black box. You can't easily trace the source of its information, making it difficult to trust, verify, or debug.
- Cost & Compute for Customization: Fine-tuning an LLM for every new domain or dataset is prohibitively expensive and resource-intensive, especially for proprietary enterprise data.
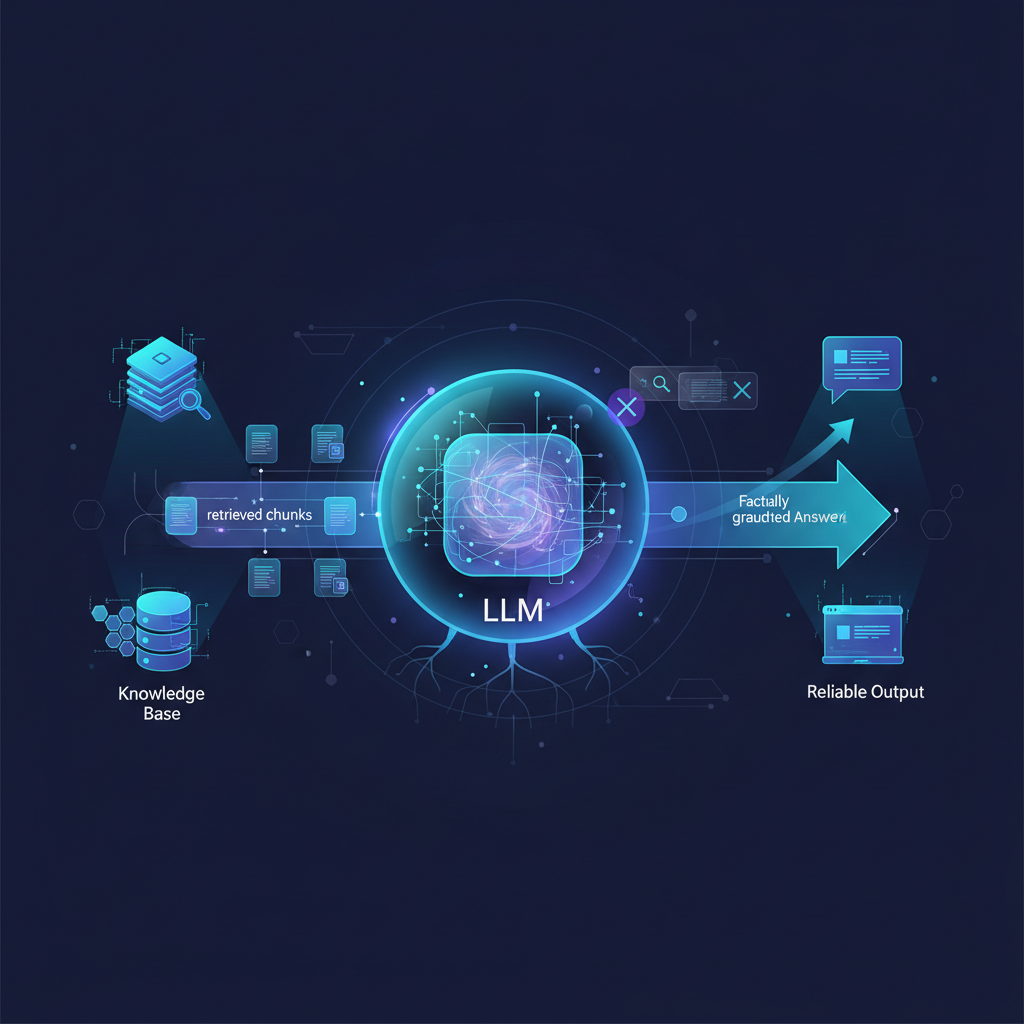
RAG elegantly circumvents these issues by providing LLMs with a dynamic, verifiable external memory, allowing them to access, synthesize, and cite up-to-date, accurate information on demand.
Deconstructing RAG: The Core Architecture
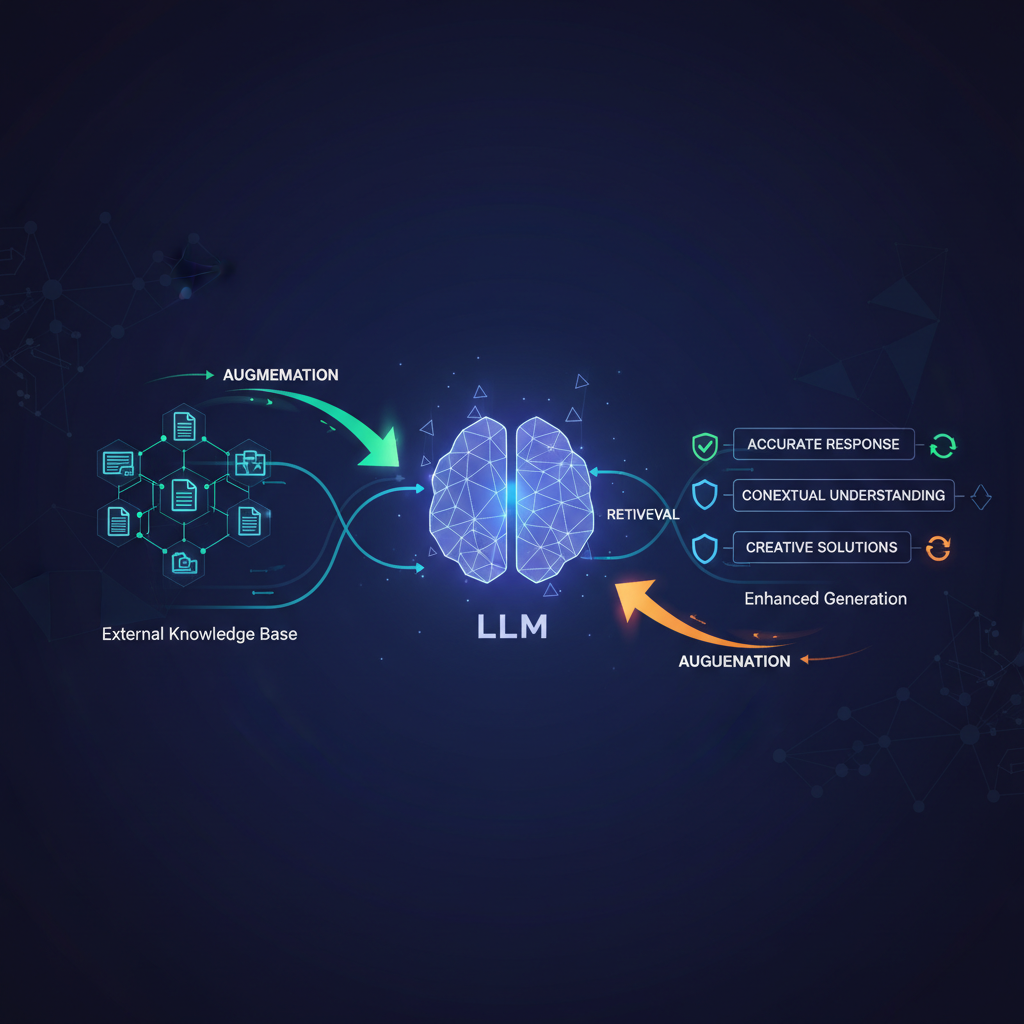
A typical RAG system operates in two main phases: Retrieval and Generation.
1. The Retrieval Phase: Finding Relevant Context
This phase is all about efficiently finding the most pertinent information from a vast corpus of documents.
-
Data Ingestion & Indexing:
- Document Loading: Your raw data, whether it's PDFs, web pages, database records, internal wikis, or legal documents, is first loaded into the system.
- Chunking: This is a critical step. Large documents are broken down into smaller, semantically coherent "chunks." The size and strategy for chunking are crucial; chunks that are too small lack context, while chunks that are too large might exceed the LLM's context window or dilute relevance. Advanced chunking strategies consider document structure, headings, and semantic boundaries.
- Embedding: Each chunk is then transformed into a high-dimensional numerical vector using an embedding model (e.g., OpenAI's
text-embedding-ada-002, SentenceTransformers, Cohere Embed). These embeddings capture the semantic meaning of the text, such that chunks with similar meanings are located closer together in the vector space. - Vector Database: These embeddings, along with references to their original text chunks, are stored in a specialized vector database (e.g., Pinecone, Weaviate, ChromaDB, FAISS, Milvus). These databases are optimized for rapid similarity searches.
-
Query Processing & Search:
- Query Embedding: When a user submits a query, it undergoes the same embedding process using the identical embedding model used for the document chunks.
- Vector Search: The query's embedding vector is then used to perform a similarity search (typically a k-nearest neighbors or k-NN search) against the vectors in the vector database. This retrieves the top
kmost semantically similar document chunks. - Re-ranking (Optional but Highly Recommended): The initial
kretrieved chunks might contain some noise or less relevant information. A more sophisticated re-ranking model (often a cross-encoder model) can be employed to re-evaluate these chunks in the context of the original query, ordering them by their fine-grained relevance. This significantly improves the quality of the context passed to the LLM.
2. The Generation Phase: Synthesizing the Answer
With the most relevant context in hand, the system now leverages an LLM to formulate a coherent and accurate answer.
- Prompt Construction: The user's original query and the top-ranked retrieved document chunks are combined into a carefully engineered prompt. This prompt typically instructs the LLM to answer the question only using the provided context, to avoid hallucination, and to cite its sources.
"Based on the following context, answer the question below. If the answer is not in the context, state that you cannot find it. Context: [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] [Retrieved Document Chunk 3] ... Question: [User's Query] Answer:""Based on the following context, answer the question below. If the answer is not in the context, state that you cannot find it. Context: [Retrieved Document Chunk 1] [Retrieved Document Chunk 2] [Retrieved Document Chunk 3] ... Question: [User's Query] Answer:" - LLM Inference: This constructed prompt is then sent to a powerful LLM (e.g., GPT-4, Claude 3, Llama 2, Mixtral). The LLM processes the prompt and generates an answer, grounded strictly in the provided context.
- Attribution: A well-designed RAG system will also present the source documents or specific passages from which the LLM drew its information, enhancing transparency and trust.
Recent Developments & Emerging Trends
RAG is a vibrant field of research and development, constantly evolving to address new challenges and unlock greater capabilities.
- Advanced Retrieval Strategies:
- Hybrid Search: Combining traditional keyword-based search (like BM25) with vector search for a more robust retrieval, leveraging both lexical and semantic matching.
- Graph-based Retrieval: Integrating knowledge graphs to retrieve structured relationships alongside unstructured text, enabling more complex reasoning.
- Multi-vector Retrieval: Representing chunks with multiple embeddings to capture different facets of meaning or to handle different query types.
- Contextual Chunking: Moving beyond fixed-size chunks to intelligent chunking that respects document structure, headings, and semantic boundaries, ensuring chunks are truly self-contained and meaningful.
- Optimizing the Generation Phase:
- Self-Correction/Self-Refinement: LLMs are prompted to critique their own initial answers against the retrieved context and then refine them, leading to more accurate and grounded responses.
- Adaptive Context Window Management: Dynamically adjusting the amount of retrieved context fed to the LLM based on query complexity, document relevance, or even the LLM's current "confidence."
- Evaluation Metrics and Frameworks: The community is developing specialized metrics (e.g., faithfulness, groundedness, context relevance, answer completeness) and frameworks (like RAGAS) to objectively evaluate RAG system performance, moving beyond traditional NLP metrics.
- Multi-modal RAG: Extending RAG to retrieve and generate information from various modalities beyond text, such as images, audio, and video. Imagine asking an LLM about a specific product, and it retrieves product images, user review videos, and technical specifications to formulate a comprehensive answer.
- Agentic RAG: This is a particularly exciting frontier. RAG is integrated into autonomous AI agents, allowing them to decide when to retrieve information, what to retrieve (e.g., specific tools or documents), and how to use that information to accomplish complex, multi-step tasks. This involves planning, tool use, and self-reflection within the agent's loop.
- Fine-tuning Retrieval Models: While the "G" part often uses a pre-trained LLM, the "R" part (the embedding model and re-ranker) can be fine-tuned on domain-specific data to significantly improve retrieval accuracy for specialized knowledge bases.
Practical Applications: Where RAG Shines
RAG's ability to ground LLMs in verifiable information makes it invaluable across a multitude of industries and use cases:
- Enterprise Knowledge Management: Building intelligent chatbots and search interfaces that can answer complex questions using internal documentation, policy manuals, HR guidelines, and proprietary databases. This reduces employee onboarding time and improves productivity.
- Example: An employee asks, "What's the process for requesting parental leave?" The RAG system retrieves relevant sections from the HR policy document and synthesizes a clear, actionable answer, citing the policy.
- Customer Support & Service: Providing accurate, up-to-date answers to customer queries, reducing agent workload, and improving customer satisfaction.
- Example: A customer asks, "How do I troubleshoot my new router model X?" The RAG system retrieves the specific troubleshooting guide for model X and provides step-by-step instructions.
- Legal & Compliance: Summarizing legal documents, answering questions based on case law, and ensuring compliance with regulations by grounding answers in specific legal texts.
- Example: A lawyer asks, "What are the precedents for contract disputes involving intellectual property in California?" The RAG system queries a legal database, retrieves relevant case summaries, and highlights key rulings.
- Healthcare & Life Sciences: Assisting medical professionals with diagnostic information, drug interactions, and research by querying vast biomedical literature and patient records (with appropriate privacy safeguards).
- Example: A doctor asks, "What are the latest treatment protocols for a specific rare disease?" The RAG system retrieves recent clinical trial results and medical journal articles.
- Education & Research: Creating personalized learning experiences, answering research questions from academic papers, and summarizing complex topics for students.
- Example: A student asks, "Explain the concept of quantum entanglement in simple terms, citing a source." The RAG system retrieves an accessible explanation from a physics textbook or reputable science website.
- Content Creation & Curation: Generating factual articles, reports, or marketing copy by pulling information from reliable sources, ensuring accuracy and reducing research time.
- Example: A marketing team needs to write an article about "sustainable farming practices." The RAG system can retrieve data on various techniques, their environmental impact, and economic viability.
- Personal Assistants: Building more capable personal AI assistants that can access and synthesize information from your personal files, emails, and browsing history (again, with robust privacy controls), acting as a true digital extension of yourself.
Challenges and Future Directions
Despite its immense potential, RAG is not without its challenges:
- Context Window Limits: While LLM context windows are growing, managing large amounts of retrieved context efficiently and ensuring the LLM focuses on the most salient parts remains a challenge, especially for highly complex queries.
- Scalability: Managing and updating massive vector databases for real-time applications, particularly with rapidly changing information, requires robust infrastructure.
- Cost: Running multiple models (embedding, re-ranker, LLM) for each query can be computationally intensive and expensive, especially at scale.
- Evaluation Complexity: Accurately evaluating the quality of RAG systems is harder than traditional NLP tasks because it involves assessing not just the answer's coherence but also its factual accuracy, groundedness in the provided context, and the relevance of the retrieved documents.
- Multi-hop Reasoning: Handling queries that require synthesizing information from multiple, disparate documents or performing multi-step logical reasoning remains an active area of research.
- Personalization: Tailoring RAG responses to individual user preferences, historical interactions, or specific roles within an organization is a key area for future development.
Conclusion
Retrieval-Augmented Generation has emerged as a cornerstone technology for making Large Language Models truly practical, reliable, and trustworthy. By addressing the critical issues of hallucination, knowledge freshness, and explainability, RAG empowers developers and organizations to build sophisticated AI applications that were previously out of reach. From enhancing enterprise knowledge management to revolutionizing customer support and enabling advanced scientific research, RAG is democratizing the power of LLMs.
As research continues to push the boundaries of retrieval sophistication, generation refinement, and integration into intelligent agents, RAG is not merely a trend; it's a fundamental architectural pattern that will continue to shape the future of AI. For any AI practitioner or enthusiast, understanding and mastering RAG is no longer optional—it's essential for building the next generation of intelligent systems.