Beyond GPT-4: The Rise of Smaller, More Efficient LLMs for Democratized AI
The era of colossal LLMs like GPT-4 has shown incredible power but comes with high costs, latency, and privacy concerns. This post explores the crucial industry pivot towards democratizing AI capabilities through smaller, more efficient models.
The era of colossal Large Language Models (LLMs) has undeniably reshaped the landscape of artificial intelligence. Models like GPT-4, Claude 3, and Gemini have showcased breathtaking capabilities, from generating coherent prose to writing code and engaging in complex reasoning. However, this power comes at a significant cost. The sheer scale of these models, often boasting hundreds of billions to trillions of parameters, necessitates immense computational resources, leading to high inference costs, noticeable latency due to cloud dependency, and legitimate concerns around data privacy and security when sensitive information is sent off-device. Moreover, their environmental footprint from training and continuous operation is substantial.
This "bigger is better" paradigm, while pushing the boundaries of AI, has also highlighted its limitations for widespread, practical deployment. The industry is now experiencing a crucial pivot: a strong movement towards democratizing LLM capabilities by making them more accessible, affordable, and deployable in resource-constrained, real-world environments. This shift is giving rise to a new generation of efficient LLMs and the burgeoning field of on-device Natural Language Processing (NLP), moving intelligence from cloud giants to the very edge of our digital lives.
The Imperative for Efficiency: Why Smaller is the New Bigger
The challenges posed by monolithic LLMs are multifaceted, driving the urgent need for efficiency:
- Computational Expense: Running inference on large models requires powerful GPUs and significant energy, translating directly into high operational costs for businesses and individuals.
- Latency & Connectivity: Cloud-based inference introduces network round-trip times, making real-time applications sluggish. Furthermore, it mandates a reliable internet connection, excluding vast swathes of potential use cases in offline or low-connectivity environments.
- Privacy and Security: For sensitive applications (e.g., healthcare, finance, personal assistants), sending data to external cloud APIs raises compliance and trust issues. Local processing eliminates this concern.
- Accessibility & Equity: High costs and infrastructure requirements create barriers to entry, limiting who can leverage these powerful technologies. Efficient models lower this barrier.
- Environmental Impact: The energy consumption associated with training and running massive models contributes to a significant carbon footprint. Smaller models inherently consume less.
Addressing these challenges is not merely an optimization problem; it's about unlocking the next wave of AI innovation, enabling ubiquitous, personalized, and private AI experiences.
Pillars of Efficiency: Innovations in Model Architecture and Optimization
The pursuit of efficient LLMs is a multi-pronged effort, involving breakthroughs in model design, compression techniques, and specialized deployment strategies.
1. Model Architecture Optimization
The fundamental design of an LLM plays a critical role in its efficiency. Researchers are exploring novel architectures that offer high performance with fewer computational demands.
-
Mixture-of-Experts (MoE) Models: Architectures like Mixtral 8x7B represent a significant leap. Instead of activating all parameters for every input, MoE models route each token through a small subset of "expert" networks. This allows for a model with a massive total parameter count (high capacity) to have a much smaller active parameter count during inference, leading to faster processing and reduced memory usage while maintaining strong performance.
- How it works: An input token is first passed through a "router" network, which determines which 1-2 "expert" sub-networks are most relevant for processing that specific token. Only these selected experts are activated, significantly reducing the computational load compared to a dense model of similar overall size.
- Example: Imagine a library with millions of books. A traditional LLM might scan every book for every query. An MoE model is like having a smart librarian who directs you to only the most relevant section or even specific books based on your query, making the search much faster.
-
Sparse Attention Mechanisms: The self-attention mechanism, a cornerstone of Transformer architectures, has a quadratic complexity with respect to sequence length. For very long inputs, this becomes a bottleneck. Sparse attention mechanisms aim to reduce this by only attending to a subset of tokens, rather than all of them, thereby reducing computational cost. Various strategies exist, such as local attention (attending only to nearby tokens) or learned sparse patterns.
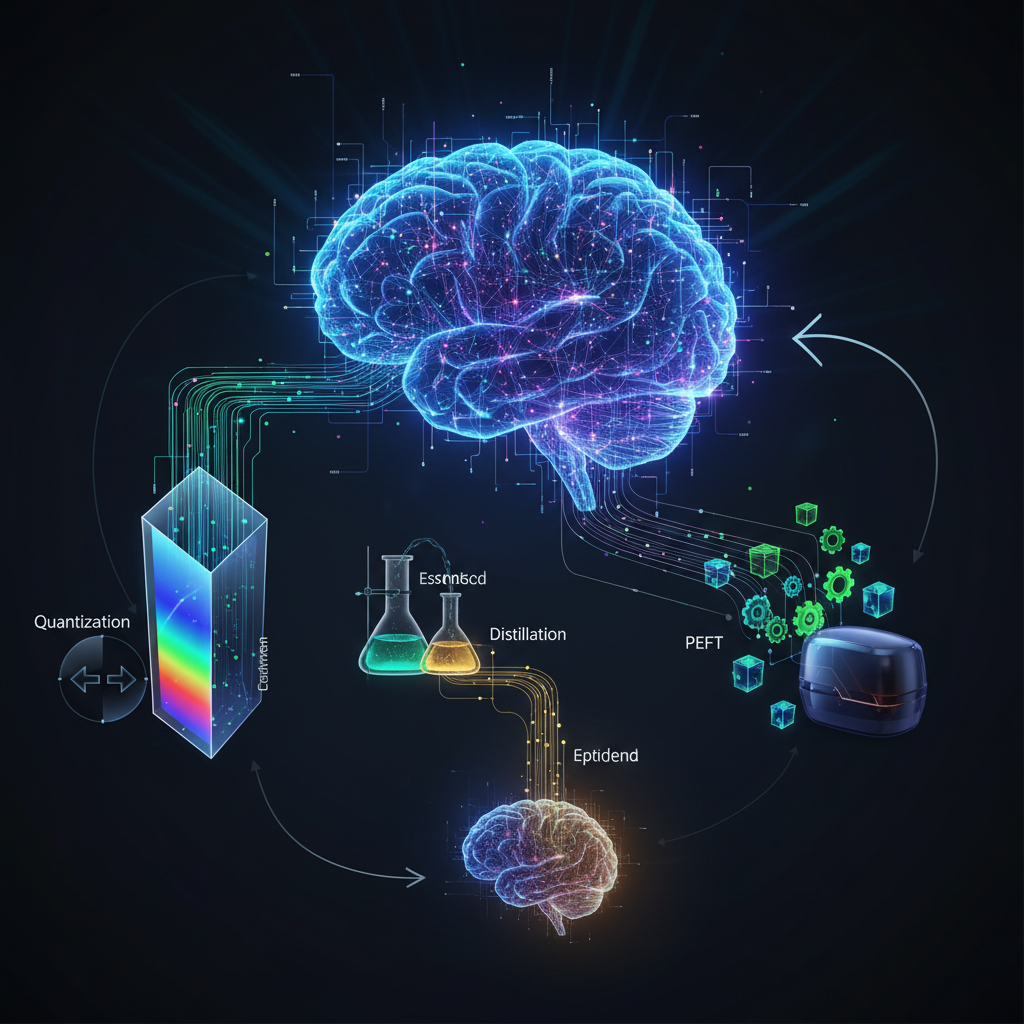
2. Model Compression Techniques
Once a model is trained, or even during training, several techniques can be applied to reduce its size and computational requirements without significant performance degradation.
-
Quantization: This is perhaps the most impactful technique for on-device deployment. It involves reducing the numerical precision of a model's weights and activations.
- FP32 (Full Precision): Standard training often uses 32-bit floating-point numbers.
- FP16/BF16 (Half Precision): Moving to 16-bit floats halves the memory footprint and can speed up computation on compatible hardware with minimal accuracy loss.
- INT8, INT4, INT2, Binary: Reducing precision further to 8-bit, 4-bit, or even 2-bit integers, or binary values, drastically shrinks model size and speeds up inference, especially on CPUs and NPUs. The challenge lies in minimizing the "quantization error" that can degrade performance. Techniques like Grouped Quantization (e.g., GGML's Q4_0, Q5_K) and AWQ (Activation-aware Weight Quantization) are crucial here.
- Practical Impact: A 7B parameter model in FP16 might be ~14GB. In INT4, it could be ~3.5GB, making it runnable on consumer laptops with 8GB RAM, or even smartphones.
-
Pruning: This technique involves removing redundant or less important weights, neurons, or even entire layers from a trained model.
- Magnitude Pruning: Removing weights with absolute values below a certain threshold.
- Structured Pruning: Removing entire channels or filters, leading to more regular sparsity that's easier for hardware to accelerate.
- Iterative Pruning and Retraining: Often, pruning is followed by a short retraining phase to recover any lost performance.
-
Distillation: This involves training a smaller "student" model to mimic the behavior of a larger, more powerful "teacher" model. The student learns not just from the teacher's final predictions but also from its intermediate representations or "soft targets" (probability distributions over classes).
- Knowledge Distillation: The student is trained to match the teacher's output probabilities.
- Feature Distillation: The student is trained to match the teacher's hidden layer activations.
- Example: A complex, large LLM (teacher) generates highly nuanced responses. A smaller LLM (student) is trained on these responses, effectively learning the "knowledge" of the larger model in a more compact form, without needing to be as large itself.
3. Smaller, High-Performing Models
Beyond architectural and compression techniques, a dedicated effort is underway to train inherently smaller models that achieve remarkable performance. This often involves meticulous data curation and novel training methodologies.
- Microsoft's Phi Series (Phi-2, Phi-3 Mini): These models demonstrate that high-quality, carefully curated training data can lead to surprisingly capable models even at small scales (e.g., 2.7B parameters for Phi-2, 3.8B for Phi-3 Mini). They focus on "textbook-quality" data, emphasizing reasoning and common sense.
- Google's Gemma: Derived from the research behind Gemini, Gemma offers open-source, lightweight models (e.g., 2B and 7B parameters) that provide strong performance benchmarks, making cutting-edge research accessible to a broader community.
- TinyLlama, StableLM-2-1.6B: These are examples of community and open-source initiatives pushing the boundaries of how small and efficient an LLM can be while retaining useful capabilities.
- Domain-Specific Small Models: For many applications, a general-purpose LLM is overkill. Training smaller models on highly specialized datasets (e.g., medical literature, legal documents, customer support transcripts) can achieve superior accuracy for that specific domain with far fewer parameters than a generalist model. This is often combined with fine-tuning.
Enabling On-Device NLP: Inference Frameworks and Hardware
The journey from a trained, efficient model to a functional on-device application requires specialized software frameworks and, increasingly, dedicated hardware.
1. Inference Optimization Frameworks & Libraries
These tools are crucial for taking a trained model and optimizing its execution on target hardware.
-
GGML/GGUF (and
llama.cpp): This ecosystem has been a game-changer for CPU-based LLM inference. GGML (Georgi Gerganov's Machine Learning library) is a C library for machine learning, and GGUF is its optimized file format for storing LLMs.llama.cppis a popular project that leverages GGML/GGUF to enable efficient inference of various LLMs (not just Llama models) on standard CPUs, often with various quantization levels.- Example: Running a 7B parameter Llama 2 model quantized to Q4_K_M (4-bit quantization with specific key/value cache handling) on a MacBook Pro's CPU, achieving several tokens per second generation speed. This was previously unthinkable without a dedicated GPU.
-
bash
# Example command using llama.cpp to run a quantized Llama 2 model ./main -m models/llama-2-7b-chat.Q4_K_M.gguf -p "What is the capital of France?" -n 128# Example command using llama.cpp to run a quantized Llama 2 model ./main -m models/llama-2-7b-chat.Q4_K_M.gguf -p "What is the capital of France?" -n 128
-
ONNX Runtime: An open-source, cross-platform inference engine that optimizes models from various frameworks (PyTorch, TensorFlow) for deployment across a wide range of hardware (CPUs, GPUs, NPUs). It converts models into the Open Neural Network Exchange (ONNX) format, which is then optimized for the target device.
-
TensorRT (NVIDIA): NVIDIA's SDK for high-performance deep learning inference. It optimizes models for NVIDIA GPUs by applying various transformations, including layer fusion, precision calibration (quantization), and kernel auto-tuning, leading to significant speedups.
-
OpenVINO (Intel): Intel's toolkit for optimizing and deploying AI inference on Intel hardware (CPUs, integrated GPUs, NPUs, FPGAs). It supports a wide range of models and provides tools for quantization and performance profiling.
-
MLC LLM: A universal deployment framework for LLMs that aims to bring "LLMs to everyone's device." It supports various hardware backends (GPUs, CPUs, Apple Neural Engine) and quantization schemes, allowing developers to compile and run LLMs efficiently on mobile phones, laptops, and web browsers.
2. Specialized Hardware & Accelerators
The rise of efficient AI has spurred innovation in hardware designed specifically for inference.
- NPUs (Neural Processing Units): Dedicated AI accelerators found in modern smartphones (e.g., Apple's Neural Engine, Qualcomm's Hexagon NPU), laptops (e.g., Intel Core Ultra with NPU), and even some embedded systems. NPUs are optimized for parallel matrix multiplications and other AI-specific operations, offering significantly higher energy efficiency and performance for AI tasks compared to general-purpose CPUs or even GPUs in certain scenarios.
- Edge AI Chips: Custom silicon designed for low-power, high-efficiency AI inference in IoT devices, smart cameras, drones, and other edge applications where power consumption and size are critical constraints.
Maintaining Performance: Smart Strategies for Smaller Models
While smaller models are inherently less capable than their colossal counterparts, intelligent techniques can bridge much of the performance gap, especially for specific tasks.
-
Retrieval Augmented Generation (RAG): This technique combines the generative power of an LLM with an external knowledge base. Instead of relying solely on the LLM's internal (and potentially outdated or limited) knowledge, RAG systems first retrieve relevant information from a document store (e.g., vector database of internal documents, web search results) and then feed this context to the LLM along with the user's query.
- Benefit: A smaller LLM, when given highly relevant context, can generate accurate and grounded responses, compensating for its limited internal knowledge. This makes it ideal for applications requiring up-to-date information or access to proprietary data.
- Example: A customer support chatbot powered by a small LLM and a RAG system can answer specific product questions by retrieving information from the company's knowledge base, providing accurate and consistent responses without needing to be trained on the entire product manual.
-
Fine-tuning and LoRA (Low-Rank Adaptation): These techniques adapt a pre-trained base model to a specific task or dataset.
- Full Fine-tuning: Adjusts all parameters of a pre-trained model on new data. This is computationally expensive.
- LoRA: A parameter-efficient fine-tuning (PEFT) method. Instead of updating all the original model's weights, LoRA injects small, trainable low-rank matrices into the Transformer layers. During fine-tuning, only these small matrices are updated, drastically reducing the number of trainable parameters and computational cost. The original model weights remain frozen.
- Benefit: LoRA allows smaller models to be quickly and cheaply adapted to highly specific domains or tasks (e.g., summarizing legal documents, generating marketing copy for a niche product) with performance often comparable to full fine-tuning, but using far fewer resources. This makes specialization accessible.
Practical Applications and Impact
The rise of efficient LLMs and on-device NLP is not just an academic exercise; it's a paradigm shift with profound practical implications across various industries and daily life.
-
Enhanced Privacy and Security:
- Healthcare: Processing patient notes, medical records, or diagnostic reports locally on a device, ensuring sensitive health information never leaves the secure environment.
- Finance: Analyzing financial transactions, detecting fraud, or providing personalized financial advice without uploading data to external servers.
- Personal Assistants: Voice assistants and smart home devices that understand and respond to commands locally, improving privacy by not sending every utterance to the cloud.
-
Reduced Latency and Real-time Interactions:
- Voice Assistants & Chatbots: Instantaneous responses for a smoother user experience, even in environments with poor or no internet connectivity.
- Real-time Transcription & Translation: On-device speech-to-text and language translation for meetings, lectures, or travel, providing immediate feedback.
- Gaming: NPCs with more sophisticated dialogue and adaptive behavior generated locally, enhancing immersion.
-
Cost Savings and Accessibility:
- Startups & SMBs: Integrating powerful NLP capabilities into products and services becomes economically viable, democratizing access to advanced AI.
- Offline Functionality: Enabling NLP features in remote areas, during travel, or in critical infrastructure where internet access is unreliable or non-existent. Think field service technicians with offline manuals.
-
Broader Deployment and New Use Cases:
- IoT Devices: Smart sensors, cameras, and embedded systems can perform local analysis (e.g., anomaly detection, voice command recognition) without constant cloud communication, reducing bandwidth and power consumption.
- Robotics & Autonomous Systems: Drones, industrial robots, and self-driving vehicles can interpret natural language commands or generate internal dialogue for decision-making in real-time, enhancing autonomy and safety.
- Smart Wearables: Watches and other wearables can offer advanced NLP features like sentiment analysis of messages or quick response generation, all on-device.
-
Sustainable AI:
- By reducing the computational resources and energy required for inference, efficient LLMs contribute to a more environmentally friendly AI ecosystem, aligning with broader sustainability goals.
The "Interesting" Factor: A New Frontier
This pivot towards efficiency is inherently fascinating because it represents a maturation of the AI field. It's a move from raw power to intelligent design, from brute-force computation to elegant engineering. It involves a compelling interplay of:
- Theoretical Computer Science: Pushing the boundaries of model compression, sparse architectures, and efficient algorithms.
- Hardware Engineering: Designing specialized chips (NPUs, edge AI accelerators) that are purpose-built for AI workloads.
- Software Development: Crafting sophisticated inference engines and deployment frameworks that bridge the gap between models and diverse hardware.
It's about solving real-world deployment challenges, making powerful AI capabilities pervasive, and ultimately, democratizing access to advanced language understanding and generation beyond the confines of hyperscale data centers. This shift empowers individual developers, small businesses, and users alike, fostering innovation at the edge.
Conclusion
The narrative of Large Language Models is evolving. While the pursuit of ever-larger, more capable models continues, a parallel and equally vital quest for efficiency is gaining unprecedented momentum. The rise of efficient LLMs and on-device NLP is not merely a technical optimization; it's a strategic imperative that addresses critical concerns around cost, latency, privacy, and accessibility.
Through innovations in model architecture like MoE, sophisticated compression techniques such as quantization and distillation, the development of smaller yet powerful models like Phi-3 and Gemma, and the advent of specialized inference frameworks and hardware, we are witnessing a profound transformation. This movement is empowering AI to move from the cloud to our pockets, our homes, and the myriad devices that populate our world. The future of AI is not just intelligent; it's also efficient, ubiquitous, and deeply integrated into the fabric of our daily lives, making powerful language capabilities truly accessible to everyone, everywhere.