Unlocking AI's Full Potential: The Powerful Synergy of LLMs and Knowledge Graphs
Large Language Models (LLMs) have revolutionized AI, but often struggle with factual accuracy and complex reasoning. Discover how combining LLMs with the structured, explicit knowledge of Knowledge Graphs (KGs) can overcome these limitations, ushering in a new era of more reliable and powerful AI systems.
The artificial intelligence landscape is in constant flux, with breakthroughs emerging at a dizzying pace. Among the most impactful recent developments are Large Language Models (LLMs), which have captivated the world with their remarkable ability to generate human-like text, answer questions, and even write code. Yet, despite their prowess, LLMs often stumble when it comes to factual accuracy, complex reasoning, and transparent explainability – issues that hinder their deployment in critical real-world applications.
Enter Knowledge Graphs (KGs). Long a cornerstone of semantic web technologies and enterprise AI, KGs offer a structured, explicit, and factual representation of knowledge. For years, they've powered sophisticated search engines, recommendation systems, and intelligent assistants. Now, as the limitations of pure LLMs become increasingly apparent, a powerful synergy is emerging: the convergence of LLMs and KGs. This fusion promises to usher in a new era of AI systems that are not only intelligent and generative but also grounded, factual, and explainable.
The Double-Edged Sword of Large Language Models
Large Language Models like GPT-4, Llama, and Claude are essentially sophisticated pattern-matching machines. Trained on colossal datasets of text and code, they excel at identifying statistical relationships between words and phrases. This enables them to perform tasks like:
- Text Generation: Crafting coherent articles, stories, and marketing copy.
- Summarization: Condensing lengthy documents into key points.
- Translation: Bridging language barriers with impressive fluency.
- Code Generation: Assisting developers by writing or debugging code snippets.
However, their statistical nature comes with significant drawbacks:
- Hallucination: LLMs can confidently generate factually incorrect or nonsensical information, as they prioritize plausible-sounding text over truth.
- Factual Inconsistency: Their knowledge is implicitly encoded in model weights, making it difficult to update or verify. They often struggle with recent events or niche domain-specific facts.
- Lack of Explainability: It's challenging to understand why an LLM produced a particular output, making them black boxes in critical applications.
- Limited Reasoning: While they can mimic reasoning patterns, true complex, multi-hop logical inference remains a challenge.
- Knowledge Cut-off: Their training data has a specific cut-off date, meaning they lack awareness of events or information beyond that point.
These limitations underscore a fundamental truth: LLMs are powerful language processors, but they are not inherently knowledge reasoners.
Knowledge Graphs: The Structured Backbone of Factual Intelligence
In contrast to the implicit, statistical knowledge of LLMs, Knowledge Graphs provide an explicit, structured, and machine-readable representation of information. At their core, KGs consist of:
- Nodes (Entities): Representing real-world objects, concepts, or abstract ideas (e.g., "Albert Einstein," "Theory of Relativity," "Germany").
- Edges (Relationships): Connecting entities and describing the nature of their association (e.g., "Albert Einstein was born in Germany," "Theory of Relativity developed by Albert Einstein").
These relationships are often expressed as RDF triples (Subject-Predicate-Object), forming a rich network of interconnected facts.
Key Characteristics of KGs:
- Explicit and Factual: Knowledge is directly asserted and verifiable.
- Structured: Information is organized according to a defined schema or ontology, enabling precise querying.
- Inferable: Rules and ontologies allow for logical deductions, generating new knowledge from existing facts.
- Traceable: The source of information can often be tracked back to its origin.
- Extensible and Updatable: New facts and relationships can be added without retraining an entire model.
Prominent examples include public KGs like Wikidata and DBpedia, which power Wikipedia's infoboxes and Google's Knowledge Panel, as well as countless proprietary enterprise KGs used for internal knowledge management.
The Synergy: How LLMs and KGs Converge
The convergence of LLMs and KGs is not about replacing one with the other, but rather about leveraging their complementary strengths. LLMs bring unparalleled natural language understanding and generation capabilities, while KGs provide the factual grounding, structured knowledge, and reasoning capabilities that LLMs often lack. This creates a powerful neuro-symbolic AI paradigm.
Here are the primary methods of convergence:
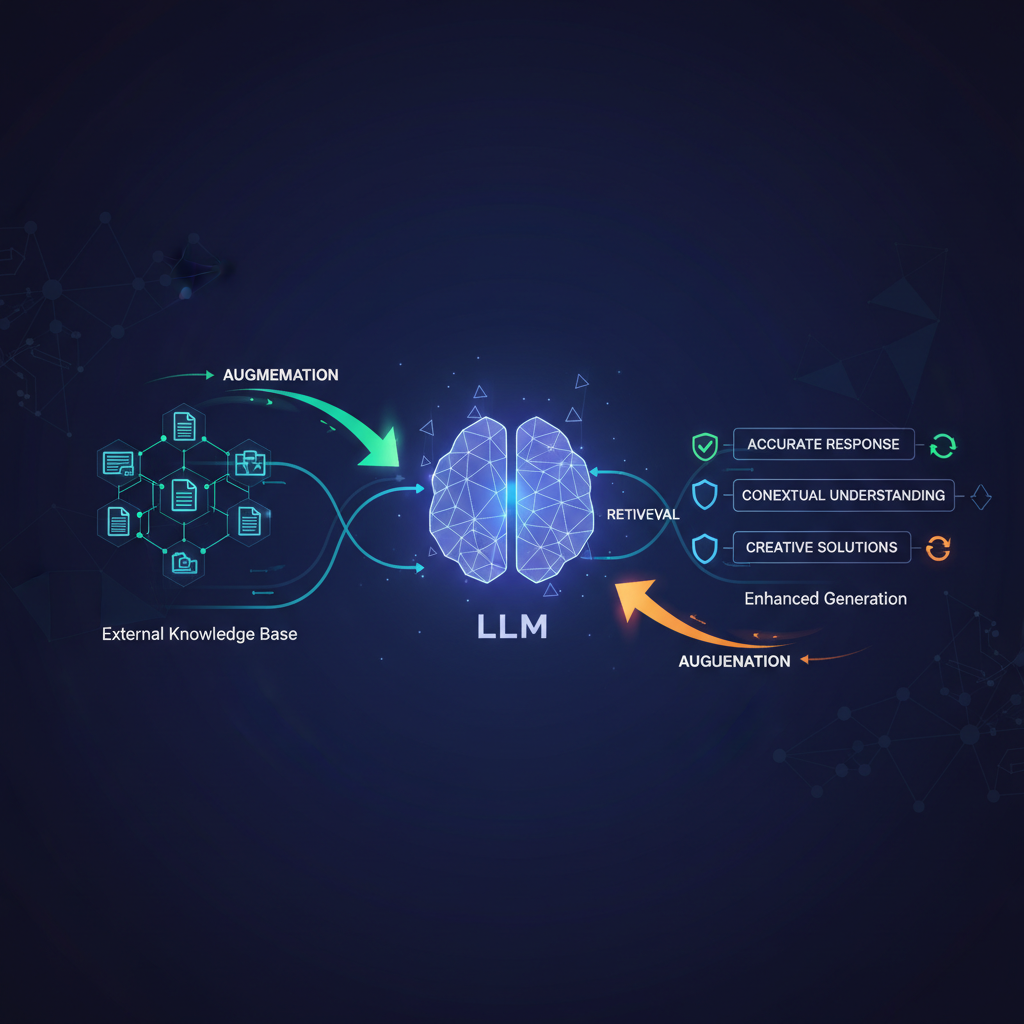
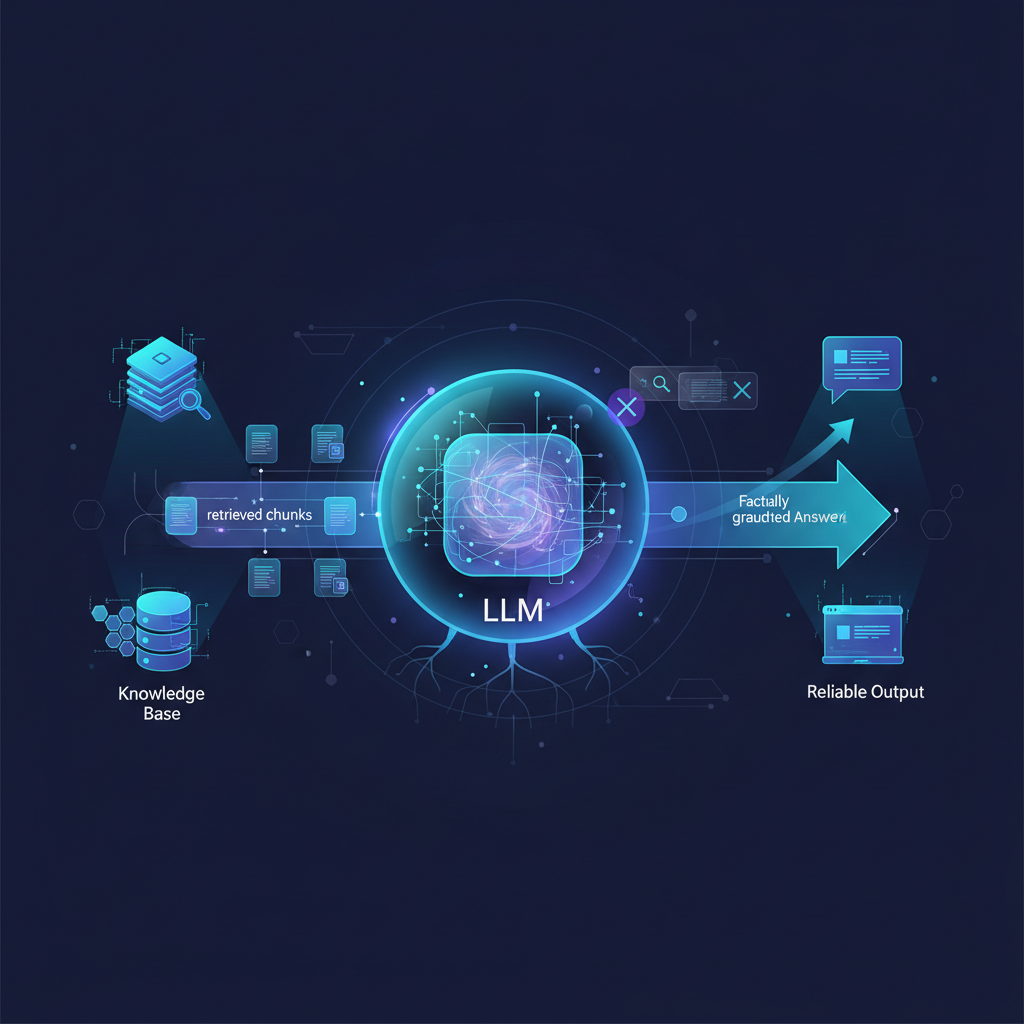
1. Retrieval-Augmented Generation (RAG)
RAG is perhaps the most widely adopted and foundational method. Instead of relying solely on its internal, implicit knowledge, an LLM is augmented with a retrieval mechanism that fetches relevant information from an external knowledge source – often a KG or a vector store derived from it.
How it works:
- User Query: A user asks a question in natural language (e.g., "Who developed the theory of general relativity and when?").
- Retrieval: The LLM (or a separate component) converts the query into an embedding or generates a query for the KG. This query retrieves relevant facts, entities, or relationships from the KG.
- Technical Detail: This might involve semantic search over vector embeddings of KG entities/relations, or the LLM generating a SPARQL/Cypher query which is then executed against the KG.
- Augmentation: The retrieved facts are then included in the prompt given to the LLM.
- Generation: The LLM uses this augmented prompt to generate a grounded, factual answer.
Example:
- User: "What are the common side effects of Metformin?"
- RAG System:
- Identifies "Metformin" as a drug entity.
- Queries a medical KG for "Metformin" and its associated "side effects" relationships.
- Retrieves triples like
(Metformin, has_side_effect, Nausea),(Metformin, has_side_effect, Diarrhea),(Metformin, has_side_effect, Abdominal Discomfort). - LLM Prompt: "Based on the following facts: Metformin has side effect Nausea. Metformin has side effect Diarrhea. Metformin has side effect Abdominal Discomfort. Please list the common side effects of Metformin."
- LLM Output: "Common side effects of Metformin include nausea, diarrhea, and abdominal discomfort."
This approach significantly reduces hallucinations and ensures answers are based on verifiable, up-to-date information.
2. KG-Enhanced Prompting and In-Context Learning
Beyond simple retrieval, LLMs can be guided more deeply by KG structures and content within their prompts.
- Structured Prompting/Query Generation: LLMs can be trained or prompted to generate queries for KGs. A user asks a question, the LLM translates it into a formal query language (like SPARQL for RDF KGs or Cypher for Neo4j), the query is executed, and the results are then used by the LLM to formulate an answer.
- Example: User: "List all movies directed by Christopher Nolan before 2010."
- LLM generates SPARQL:
SELECT ?movie WHERE { ?movie :directedBy :ChristopherNolan . ?movie :releaseYear ?year . FILTER (?year < 2010) } - KG executes query, returns results.
- LLM formats results into natural language.
- LLM generates SPARQL:
- Example: User: "List all movies directed by Christopher Nolan before 2010."
- Fact Injection & Constraint-Based Generation: Relevant KG triples can be directly injected into the LLM's prompt to "ground" its generation. Furthermore, KG rules or constraints can be provided to the LLM, guiding its output to ensure factual consistency or adherence to specific domain logic.
3. LLM-Powered KG Construction and Enrichment
The relationship isn't one-way. LLMs can also be instrumental in building, populating, and refining KGs.
- Information Extraction (IE): LLMs excel at extracting structured information (entities, relationships, events) from unstructured text (documents, articles, web pages) to populate new KGs or enrich existing ones. This automates a traditionally labor-intensive process.
- Schema Alignment/Mapping: Different KGs or data sources often use varying terminologies. LLMs can help identify equivalent concepts and properties across schemas, facilitating integration.
- Knowledge Graph Question Answering (KGQA): While related to RAG, KGQA specifically focuses on answering natural language questions by converting them into KG queries, executing them, and then translating the structured results back into natural language.
4. Joint Embeddings and Graph Neural Networks (GNNs) with LLMs
For deeper integration, researchers are exploring architectures that combine the strengths of both paradigms more intrinsically.
- Graph Embeddings: KGs can be converted into dense vector representations (embeddings) where entities and relationships are represented in a continuous vector space. These graph embeddings can then be combined with text embeddings from LLMs.
- GNN-LLM Architectures: Graph Neural Networks (GNNs) are neural networks designed to operate directly on graph structures, capturing complex relational patterns. Integrating GNNs with transformer-based LLMs allows for joint reasoning over both textual and structural knowledge, enabling more sophisticated multi-hop reasoning. This represents a true neuro-symbolic approach, where symbolic knowledge (KG) is processed by neural networks (GNNs) and integrated with language models.
Practical Applications and Transformative Use Cases
The convergence of LLMs and KGs is not merely an academic exercise; it's driving tangible improvements across numerous industries.
-
Enterprise Knowledge Management:
- Accurate Chatbots: Grounding internal chatbots with a company's KG (e.g., HR policies, product specifications, IT troubleshooting guides) prevents "made-up" answers and provides precise, up-to-date information to employees and customers.
- Intelligent Search: Moving beyond keyword matching to semantic search, allowing users to ask complex questions and retrieve highly relevant, fact-checked information from vast internal data repositories.
- Automated Report Generation: Generating factual, consistent reports and summaries from internal data, ensuring accuracy and reducing manual effort.
-
Healthcare and Life Sciences:
- Drug Discovery: Combining LLMs' ability to process vast scientific literature with KGs of biomedical entities (genes, proteins, diseases, drugs, clinical trials) to identify novel drug targets, predict interactions, and accelerate research.
- Clinical Decision Support: Providing clinicians with evidence-based recommendations by querying medical KGs (e.g., disease pathways, treatment guidelines) and summarizing findings with LLMs, leading to more informed patient care.
-
Financial Services:
- Fraud Detection: Identifying complex, multi-hop patterns of fraudulent activity by reasoning over financial transaction KGs using LLMs to interpret anomalies and generate alerts.
- Risk Assessment: Analyzing market data, regulatory KGs, and news feeds to assess financial risks and generate nuanced insights, helping institutions make better investment and lending decisions.
-
Legal Tech:
- Contract Analysis: Using LLMs to extract key clauses, obligations, and entities from legal documents to build KGs, then querying these KGs to answer complex legal questions, identify precedents, or compare contracts.
- Case Law Research: Enhancing legal research with semantic search and summarization of legal precedents, making it faster and more accurate for legal professionals.
-
Scientific Research:
- Hypothesis Generation: Discovering novel connections between scientific concepts by combining LLM's ability to read vast amounts of literature with structured scientific KGs, accelerating discovery.
- Data Integration: Harmonizing data from disparate scientific databases into a unified KG, then querying it with natural language to uncover new insights.
-
Personalized Experiences:
- Recommendation Systems: Combining user preferences (analyzed by LLMs) with product or content KGs for more nuanced, transparent, and explainable recommendations in e-commerce, media, and other domains.
Challenges and the Road Ahead
While the convergence of LLMs and KGs offers immense promise, several challenges remain:
- Scalability: Managing and querying extremely large KGs efficiently, especially when integrating with real-time LLM interactions, can be computationally intensive.
- KG Construction and Maintenance: Building high-quality, comprehensive KGs is a significant undertaking. While LLMs can assist, ongoing maintenance and updating remain resource-intensive.
- Bridging the Semantic Gap: Effectively translating the ambiguity of natural language queries into the precision of formal KG query languages (and vice-versa) is still an active research area.
- Evaluation Metrics: Developing robust metrics to evaluate the performance of these hybrid systems, particularly for complex reasoning, explainability, and factual accuracy, is crucial.
- Computational Cost: The combined computational demands of running complex KG queries and LLM inferences can be substantial.
- Ethical Considerations: Ensuring fairness, transparency, and mitigating biases inherited from both LLM training data and KG construction is paramount, especially in critical applications.
- Dynamic Knowledge: Integrating real-time or rapidly changing information into KGs and ensuring LLMs leverage it effectively presents a challenge for maintaining up-to-date knowledge.
Conclusion: The Future is Grounded and Explainable
The convergence of Large Language Models and Knowledge Graphs represents a critical step forward in the evolution of artificial intelligence. It moves us beyond the impressive but often unreliable "parroting" of pure LLMs towards systems that can truly understand, reason, and explain their outputs based on verifiable facts.
This neuro-symbolic approach offers a compelling pathway to address the most pressing limitations of current LLMs: hallucination, lack of grounding, and opacity. By marrying the generative power of LLMs with the structured wisdom of KGs, we are building AI systems that are not only more intelligent and capable but also more trustworthy, reliable, and ultimately, more useful for humanity. As research in this area continues to flourish, we can expect to see increasingly sophisticated and impactful applications across every domain, ushering in an era of truly grounded and explainable AI.