Unlocking LLM Accuracy: How Retrieval-Augmented Generation (RAG) Combats Hallucinations
Large Language Models (LLMs) excel at generation but struggle with factual accuracy and up-to-date knowledge. Discover how Retrieval-Augmented Generation (RAG) combines LLM power with information retrieval to overcome hallucinations and enhance reliability.
The era of Large Language Models (LLMs) has ushered in unprecedented capabilities for natural language understanding and generation. From writing creative content to summarizing complex documents, LLMs have demonstrated a remarkable fluency that often blurs the line between artificial and human intelligence. However, beneath this impressive facade lies a significant challenge: LLMs, by their very nature, are prone to "hallucinations" – generating plausible-sounding but factually incorrect information. Furthermore, their knowledge is limited to their training data, leaving them oblivious to recent events or domain-specific nuances not present in their pre-training corpus. This inherent limitation has been a major hurdle for deploying LLMs in critical, fact-sensitive applications.
Enter Retrieval-Augmented Generation (RAG), a paradigm shift that marries the generative power of LLMs with the factual accuracy and up-to-dateness of information retrieval systems. RAG is rapidly becoming the go-to architecture for building robust, reliable, and trustworthy LLM-powered applications. It's not just a theoretical concept; it's a practical framework that addresses core LLM weaknesses, making it an indispensable tool for anyone looking to build production-ready AI solutions. This blog post will delve deep into RAG, exploring its mechanics, its profound impact, and the exciting advancements shaping its future.
Understanding Retrieval-Augmented Generation (RAG)
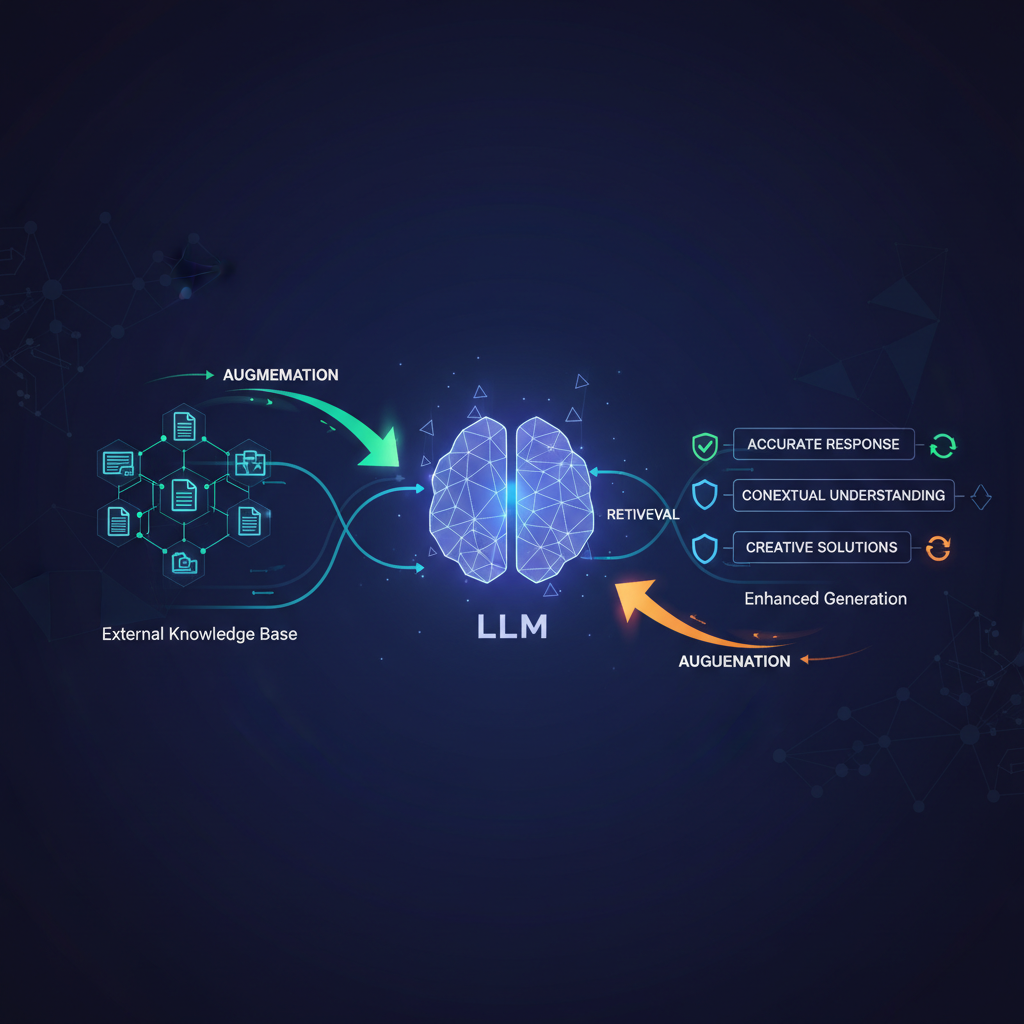
At its heart, RAG is an intelligent framework designed to enhance the capabilities of Large Language Models by providing them with access to external, authoritative knowledge sources at the moment of inference. Instead of relying solely on the vast but static knowledge embedded within their billions of parameters during pre-training, RAG systems dynamically fetch relevant information from a curated knowledge base and present it to the LLM as context. This "grounding" in external data allows the LLM to generate responses that are not only coherent and fluent but also factually accurate and up-to-date.
The core idea is elegantly simple yet profoundly impactful: combine the powerful reasoning and generative capabilities of LLMs with the factual accuracy and real-time relevance of information retrieval systems. Imagine an LLM not as an isolated genius trying to recall everything, but as a brilliant researcher who knows how to find and synthesize information from a vast, ever-growing library.
Why RAG is a Game-Changer
The rise of RAG is not coincidental; it directly addresses several critical pain points associated with standalone LLMs:
- Combating Hallucinations: This is arguably RAG's most significant contribution. By grounding responses in verifiable external data, RAG drastically reduces the LLM's tendency to invent facts or generate misleading information. The LLM is forced to "reason" over provided evidence rather than fabricating it.
- Overcoming Knowledge Cutoffs: Pre-trained LLMs have a fixed knowledge cutoff date (e.g., GPT-4's knowledge might be limited to early 2023). RAG allows systems to incorporate the latest information, real-time data, or even proprietary, internal documents that were never part of the LLM's original training.
- Enabling Domain-Specific Expertise: General-purpose LLMs lack deep expertise in niche domains like specific medical literature, internal company policies, or proprietary product documentation. RAG transforms them into highly effective domain experts by feeding them curated, relevant knowledge bases.
- Enhancing Explainability and Trust: A key benefit of RAG is the ability to cite sources. By presenting the retrieved documents alongside the generated answer, users can verify the information, trace its origin, and build greater trust in the LLM's output. This moves LLMs from black boxes to more transparent systems.
- Cost-Effectiveness and Agility: While fine-tuning an LLM can adapt it to specific data, it's often computationally expensive and time-consuming. RAG offers a more agile and cost-effective alternative for integrating new or frequently updated information without needing to retrain or fine-tune the entire model. It also avoids "catastrophic forgetting," a phenomenon where fine-tuning on new data can degrade performance on previously learned tasks.
- Rapid Prototyping and Deployment: RAG architectures streamline the development of robust, enterprise-grade LLM applications. Developers can quickly integrate new knowledge bases without altering the core LLM, accelerating development cycles.
Technical Deep Dive: The RAG Pipeline
A typical RAG system operates through a sophisticated, multi-stage workflow, involving several specialized components working in concert. Let's break down each stage:
1. Knowledge Base (Corpus) Preparation
Before retrieval can occur, you need a well-organized and relevant knowledge base. This is the foundation of your RAG system.
- Data Sources: This can be incredibly diverse, ranging from structured data (databases, APIs, spreadsheets) to unstructured documents (PDFs, Word documents, web pages, internal wikis, research papers, emails, chat logs). The quality and relevance of your source data directly impact the RAG system's performance.
- Preprocessing: Raw data is rarely suitable for direct use. It needs cleaning, parsing, and, most critically, chunking.
- Cleaning: Removing irrelevant metadata, formatting issues, or boilerplate text.
- Parsing: Extracting the core textual content from various file formats.
- Chunking: Dividing large documents into smaller, semantically meaningful segments or "chunks." This is a crucial step because LLMs have context window limits. A chunk should be small enough to fit within the LLM's context window but large enough to retain sufficient semantic meaning.
- Example: Instead of feeding an entire 50-page PDF, you might break it into paragraphs or sections. A chunk size of 200-500 tokens with some overlap (e.g., 10-20% overlap between chunks) is a common starting point, but optimal size is highly dependent on the data and use case.
- Advanced Chunking: Recent advancements explore more intelligent chunking strategies, such as recursive chunking (breaking large chunks into smaller ones if needed), semantic chunking (using LLMs to identify natural semantic boundaries), or summary-based chunks (generating a summary for each chunk and embedding that summary).
2. Indexing (Vector Database / Vector Store)
Once your knowledge base is chunked, it needs to be indexed in a way that allows for efficient semantic search.
- Embedding Model: Each text chunk is transformed into a high-dimensional numerical vector called an embedding. This is done using a specialized neural network, known as an embedding model (e.g., OpenAI's
text-embedding-ada-002, Google's PaLM Embeddings, Cohere Embed, Sentence-BERT, or various open-source models likeall-MiniLM-L6-v2). These models are trained to map semantically similar texts to vectors that are close to each other in the high-dimensional space.- Example: The sentence "The cat sat on the mat" and "A feline rested on the rug" would have very similar embeddings, even though their exact wordings differ.
- Vector Database: These embeddings, along with their original text content and any relevant metadata (e.g., source document, page number, author), are stored in a specialized vector database (also known as a vector store or vector index). Popular choices include Pinecone, Weaviate, Milvus, ChromaDB, Qdrant, and FAISS (for in-memory or self-hosted solutions). Vector databases are optimized for performing rapid similarity searches across millions or even billions of vectors.
3. Retrieval Stage
This is where the magic of finding relevant information happens.
- User Query Embedding: When a user poses a question or query, it undergoes the same embedding process as the knowledge base chunks. It's transformed into a query embedding using the exact same embedding model used during indexing. This ensures that the query and document chunks are represented in the same semantic space.
- Similarity Search: The query embedding is then used to perform a similarity search against all the document embeddings stored in the vector database. Common similarity metrics include cosine similarity, dot product, or Euclidean distance. The goal is to find document chunks whose embeddings are closest to the query embedding, indicating semantic relevance.
- Top-K Retrieval: The system retrieves the top
kmost semantically similar text chunks (documents or passages) from the knowledge base. The value ofkis a hyperparameter that balances recall (getting enough relevant information) and precision (avoiding too much irrelevant information). - Re-ranking (Optional but Recommended): Often, the initial
kretrieved documents might contain some noise or be sub-optimally ordered. A smaller, more sophisticated re-ranking model (e.g., a cross-encoder model likems-marco-TinyBERT-L-2-v2) can be applied to thesekdocuments. This model takes the query and each retrieved document pair and scores their relevance more finely, often leading to a more precise ordering and improved context quality for the LLM.
4. Generation Stage
With the relevant context in hand, the LLM can now generate an informed response.
- Context Augmentation: The retrieved
ktext chunks (potentially re-ranked) are combined with the original user query to form an augmented prompt. This prompt is carefully engineered to instruct the LLM to use the provided context.- Example Prompt Structure:
"You are an expert assistant. Based on the following context, answer the question accurately, concisely, and cite your sources if possible. If the context does not contain the answer, state that you don't know. Context: [Retrieved Document 1 Text] [Retrieved Document 2 Text] ... [Retrieved Document K Text] Question: [User's Original Query]""You are an expert assistant. Based on the following context, answer the question accurately, concisely, and cite your sources if possible. If the context does not contain the answer, state that you don't know. Context: [Retrieved Document 1 Text] [Retrieved Document 2 Text] ... [Retrieved Document K Text] Question: [User's Original Query]"
- Example Prompt Structure:
- LLM Inference: This augmented prompt is then fed to the Large Language Model (e.g., GPT-4, Llama 2, Claude 2, Mistral). The LLM processes the prompt, paying close attention to the provided context.
- Response Generation: The LLM generates a response that is "grounded" in the provided context. Because it's explicitly instructed to use the context and potentially cite sources, the likelihood of hallucinations is significantly reduced, and the factual accuracy is greatly improved.
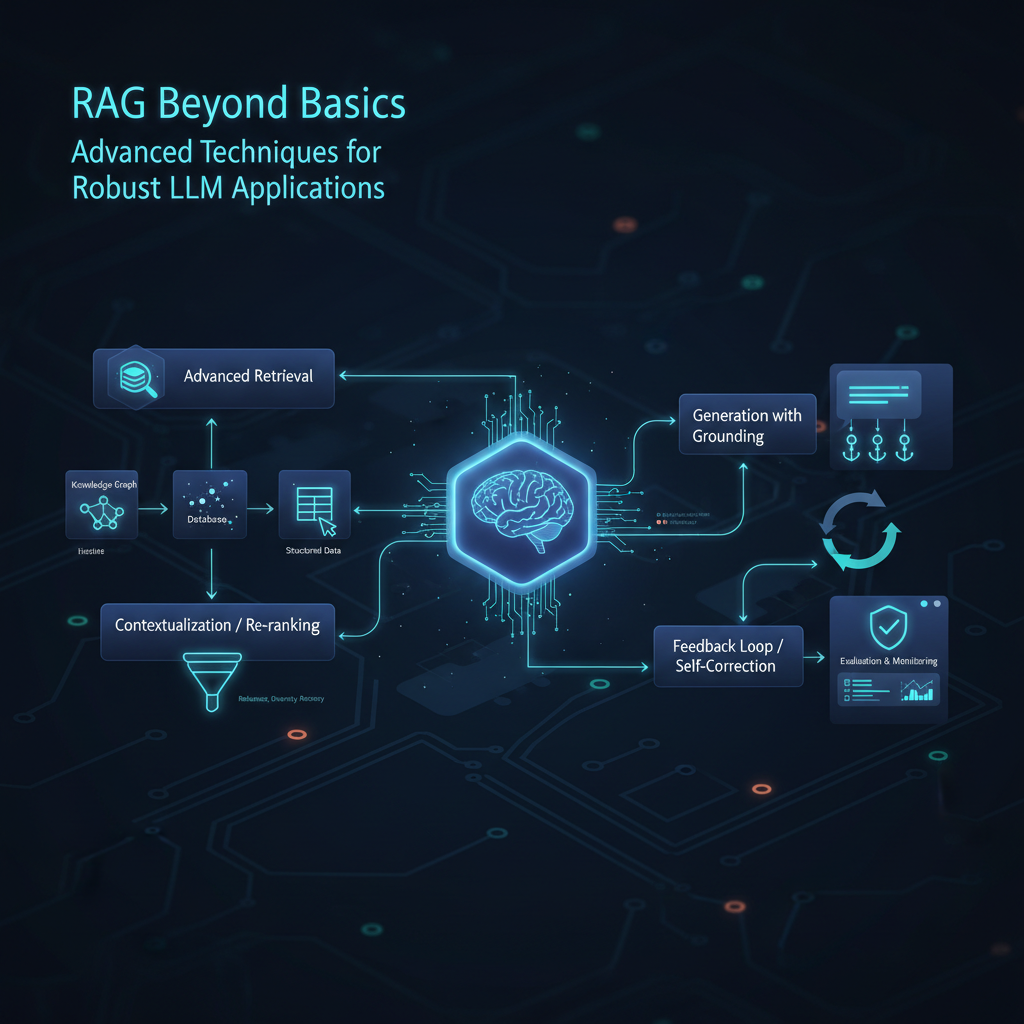
Recent Developments and Emerging Trends in RAG
RAG is a rapidly evolving field. Researchers and practitioners are constantly innovating to make RAG systems more robust, efficient, and intelligent.
- Advanced Chunking Strategies: Moving beyond simple fixed-size chunks, new methods consider document structure (headings, paragraphs), semantic boundaries (using LLMs to identify coherent sections), and even recursive chunking (breaking large chunks into smaller ones if a query is very specific, or combining small chunks for broader queries).
- Hybrid Retrieval: Combining the strengths of vector similarity search (semantic understanding) with traditional keyword-based search (e.g., BM25, TF-IDF) for improved recall. Keyword search is excellent for specific entities or rare terms, while vector search handles synonyms and conceptual queries.
- Multi-Modal RAG: Extending RAG beyond text to incorporate other modalities like images, audio, or video. Imagine asking an LLM about a product, and it retrieves both relevant text descriptions and product images to answer your query.
- Query Transformation/Expansion: Techniques to improve retrieval by rephrasing or expanding the user's initial query before embedding. This can involve using an LLM to generate multiple relevant sub-questions, identify key entities, or rephrase the query for better semantic matching.
- Contextual Compression/Summarization: Even with growing context windows, it's beneficial to compress or summarize retrieved documents, especially for very long ones. This ensures that only the most salient information is passed to the LLM, reducing token usage, latency, and the risk of the "lost in the middle" problem.
- Self-Correction and Self-Refinement (RAG with Agents): Integrating RAG into autonomous agent architectures. Here, the LLM acts as an agent that decides when to retrieve, what to retrieve, and how to synthesize information. It can even evaluate its own generated answer against the retrieved context, potentially triggering another retrieval-generation cycle if the initial answer is unsatisfactory or if more information is needed. This creates a feedback loop for continuous improvement.
- Evaluation Metrics for RAG: Developing robust metrics beyond traditional NLP metrics to assess the factual accuracy, faithfulness to sources, and completeness of RAG-generated answers. Frameworks like RAGAS (Retrieval Augmented Generation Assessment) are emerging to provide quantitative measures for RAG system quality.
- Knowledge Graph Integration: Combining RAG with knowledge graphs to provide structured, factual context. This can help LLMs with complex reasoning tasks that require understanding relationships between entities.
Practical Applications and Use Cases
RAG's versatility makes it applicable across a vast array of industries and use cases, transforming how we interact with information.
- Enterprise Search & Q&A: Imagine an intelligent chatbot for a large corporation that can answer employee questions based on internal HR policies, IT documentation, product manuals, or legal guidelines. RAG ensures these answers are accurate and up-to-date.
- Example: An employee asks, "What is the policy for remote work reimbursement?" The RAG system retrieves the latest HR policy document sections on remote work expenses and the LLM synthesizes a clear answer.
- Customer Support & Service: Automating responses to customer queries by retrieving relevant information from FAQs, product specifications, troubleshooting guides, and knowledge bases. This reduces agent workload and improves response times.
- Example: A customer asks, "How do I troubleshoot my new router's Wi-Fi connection?" The RAG system finds relevant sections from the router's manual and support articles, and the LLM provides step-by-step instructions.
- Medical & Legal Research: Assisting professionals in quickly finding and synthesizing information from vast libraries of medical journals, patient records (anonymized), legal precedents, and case studies.
- Example: A doctor queries, "What are the latest treatment protocols for Type 2 Diabetes with renal complications?" The RAG system retrieves recent clinical guidelines and research papers, allowing the LLM to summarize current best practices.
- Financial Analysis & Market Intelligence: Providing up-to-date market insights, company reports, news articles, and regulatory filings to LLMs for analysis, trend prediction, and report generation.
- Example: An analyst asks, "Summarize the Q3 earnings report for Company X, focusing on revenue growth and future outlook." The RAG system retrieves the latest earnings report and relevant financial news, enabling the LLM to generate a concise summary.
- Content Generation & Curation: Generating articles, reports, or summaries that are factually accurate and grounded in specific source materials, rather than relying on the LLM's pre-trained knowledge alone.
- Example: A content creator needs an article on "The history of quantum computing." The RAG system retrieves academic papers, historical accounts, and reputable articles, allowing the LLM to generate a well-researched and cited piece.
- Personalized Education & E-learning: Creating adaptive learning systems that retrieve relevant educational content, explanations, or practice problems based on a student's progress, learning style, and specific questions.
- Example: A student asks, "Can you explain Newton's Third Law in simpler terms with an everyday example?" The RAG system retrieves various explanations and examples from textbooks and educational resources, and the LLM tailors an explanation for the student.
- Data Analysis & Reporting: Allowing users to query complex datasets or data warehouses in natural language, with RAG retrieving relevant data snippets, schema information, or data dictionaries to guide the LLM's analysis and report generation.
Challenges and Considerations
While RAG offers immense potential, its implementation is not without its complexities and considerations.
- Chunking Strategy: This remains a critical hyperparameter. Too small, and context might be fragmented; too large, and irrelevant information might dilute the prompt or exceed context window limits. Finding the optimal balance often requires experimentation and domain expertise.
- Embedding Model Choice: The quality of your embeddings directly dictates the relevance of your retrieval. Choosing an embedding model that is well-suited to your domain, language, and data type is paramount. Generic models might underperform on highly specialized jargon.
- Knowledge Base Maintenance: Keeping the knowledge base up-to-date, clean, and well-structured is an ongoing operational challenge. Data freshness, versioning, and quality control are crucial for maintaining the RAG system's accuracy.
- Latency: The retrieval step adds latency to the overall response time compared to a standalone LLM call. Optimizing vector database performance, retrieval algorithms, and potentially pre-fetching strategies is important for real-time applications.
- Context Window Limits: While LLM context windows are growing, they still have practical limits. For very information-dense queries or extremely long documents, effective context summarization, selective retrieval, or multi-hop reasoning becomes necessary.
- "Lost in the Middle": Even with perfect retrieval, LLMs can sometimes struggle to utilize crucial information if it's buried in the middle of a very long context window. Prompt engineering, re-ranking, and techniques like "attention sinks" are being explored to mitigate this.
- Cost: Running multiple components (embedding models, vector databases, LLM calls) can accumulate costs, especially at scale. Optimizing the number of retrieved chunks, using smaller, more efficient embedding models, and leveraging open-source LLMs can help manage expenses.
- Hallucinations from Retrieved Context: While RAG reduces LLM-generated hallucinations, it doesn't eliminate the possibility of the LLM misinterpreting or misrepresenting the provided context. Robust prompt engineering and evaluation are still necessary.
Conclusion
Retrieval-Augmented Generation is more than just a technique; it's a fundamental shift in how we build and deploy Large Language Models. By systematically addressing the inherent limitations of standalone LLMs – their propensity to hallucinate and their static knowledge base – RAG empowers us to create AI applications that are not only intelligent and fluent but also reliable, factual, and trustworthy.
For AI practitioners, understanding and mastering RAG is no longer optional; it's essential. It provides the architectural blueprint for moving beyond basic LLM prompting to constructing robust, production-ready systems capable of tackling real-world challenges across diverse domains. The continuous innovation in RAG, from intelligent chunking and hybrid retrieval to multi-modal extensions and agentic self-correction, promises an even more powerful and versatile future for generative AI. As we continue to push the boundaries of what LLMs can achieve, RAG will undoubtedly remain at the forefront, guiding us toward a future where AI systems are not just intelligent, but truly informed.