Unlocking LLM Accuracy: How Retrieval-Augmented Generation (RAG) Solves Key Challenges
Large Language Models (LLMs) offer incredible potential but struggle with hallucinations and outdated knowledge. Discover how Retrieval-Augmented Generation (RAG) fundamentally transforms LLMs, grounding their responses in verifiable, external data for enhanced accuracy and reliability.
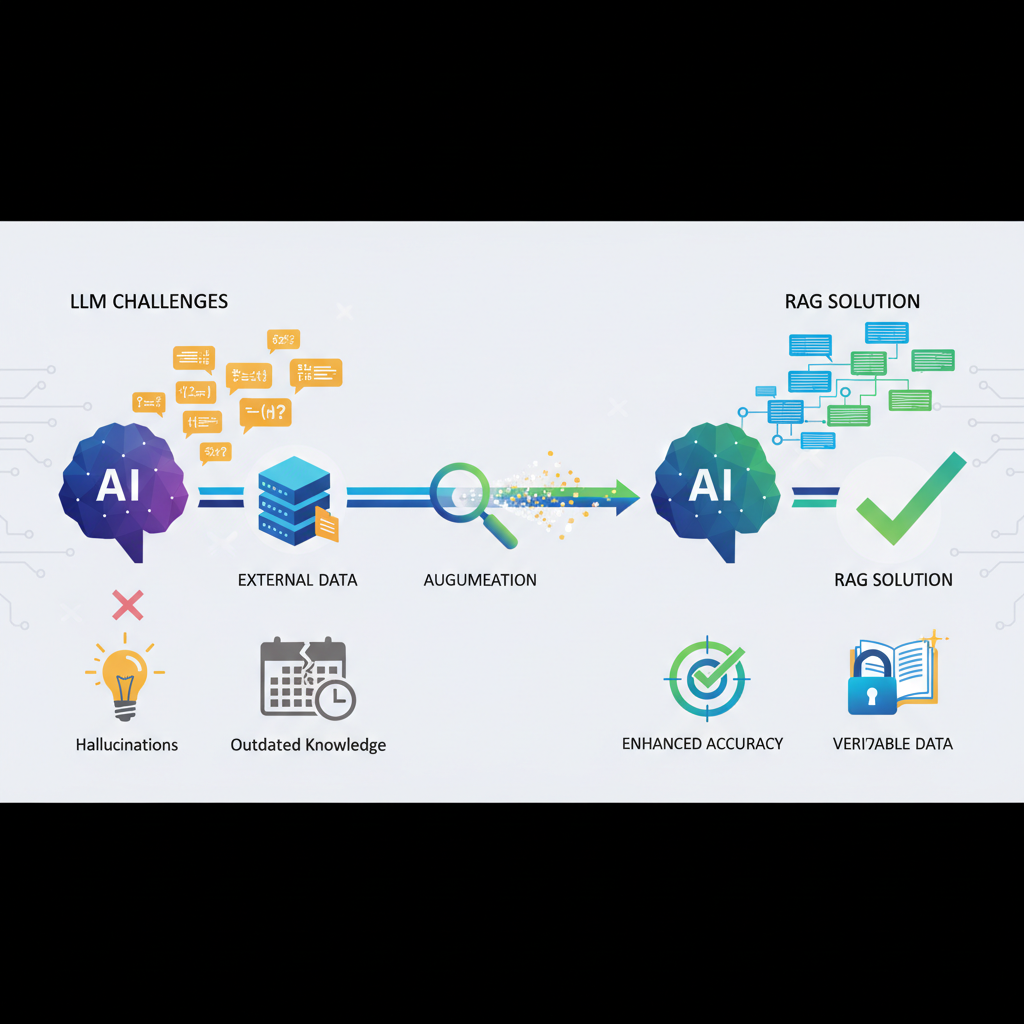
The era of Large Language Models (LLMs) has ushered in unprecedented capabilities in natural language understanding and generation. From writing poetry to generating code, LLMs have demonstrated a remarkable ability to process and produce human-like text. However, their widespread adoption in critical, real-world applications has been tempered by several inherent limitations. These include a propensity for "hallucinations" (generating factually incorrect information), a lack of up-to-date knowledge (as they are trained on static datasets), and a general opaqueness regarding the sources of their information.
Enter Retrieval-Augmented Generation (RAG). RAG is not merely an optimization; it's a fundamental architectural pattern that addresses these core challenges head-on. By dynamically fetching relevant, external information and grounding the LLM's responses in this verifiable data, RAG transforms LLMs from impressive but sometimes unreliable generalists into powerful, accurate, and transparent domain-specific experts. It's rapidly becoming an indispensable technique for anyone looking to deploy LLMs in production environments, making it a cornerstone for practical AI development.
The Genesis of RAG: Why Traditional LLMs Fall Short
To understand the power of RAG, it's crucial to first grasp the inherent limitations of standalone LLMs:
- Hallucinations: LLMs are trained to predict the next most probable word based on patterns learned from vast datasets. While this leads to fluent and coherent text, it doesn't guarantee factual accuracy. If the training data contains biases, errors, or insufficient information on a topic, the LLM might "make up" plausible-sounding but incorrect facts. This is particularly problematic in sensitive domains like healthcare or finance.
- Stale Knowledge: The knowledge cutoff date is a well-known constraint for most pre-trained LLMs. They cannot access information beyond their last training update. This means they are inherently unaware of recent events, new research, or proprietary company data, rendering them unsuitable for applications requiring real-time or domain-specific knowledge.
- Lack of Transparency and Explainability: When an LLM provides an answer, it's often a black box. Users can't easily trace the source of the information, making it difficult to verify its accuracy or trust the output. This lack of attribution is a significant barrier to enterprise adoption.
- Cost and Complexity of Fine-tuning: While fine-tuning an LLM on specific data can inject domain knowledge, it's an expensive, computationally intensive process requiring significant amounts of high-quality, labeled data. It's also not ideal for rapidly changing information or small, niche datasets.
- Context Window Limitations: Even with increasingly larger context windows, there's a practical limit to how much information an LLM can process at once. Feeding an entire knowledge base into the prompt is infeasible and inefficient. RAG intelligently selects only the most pertinent pieces of information.
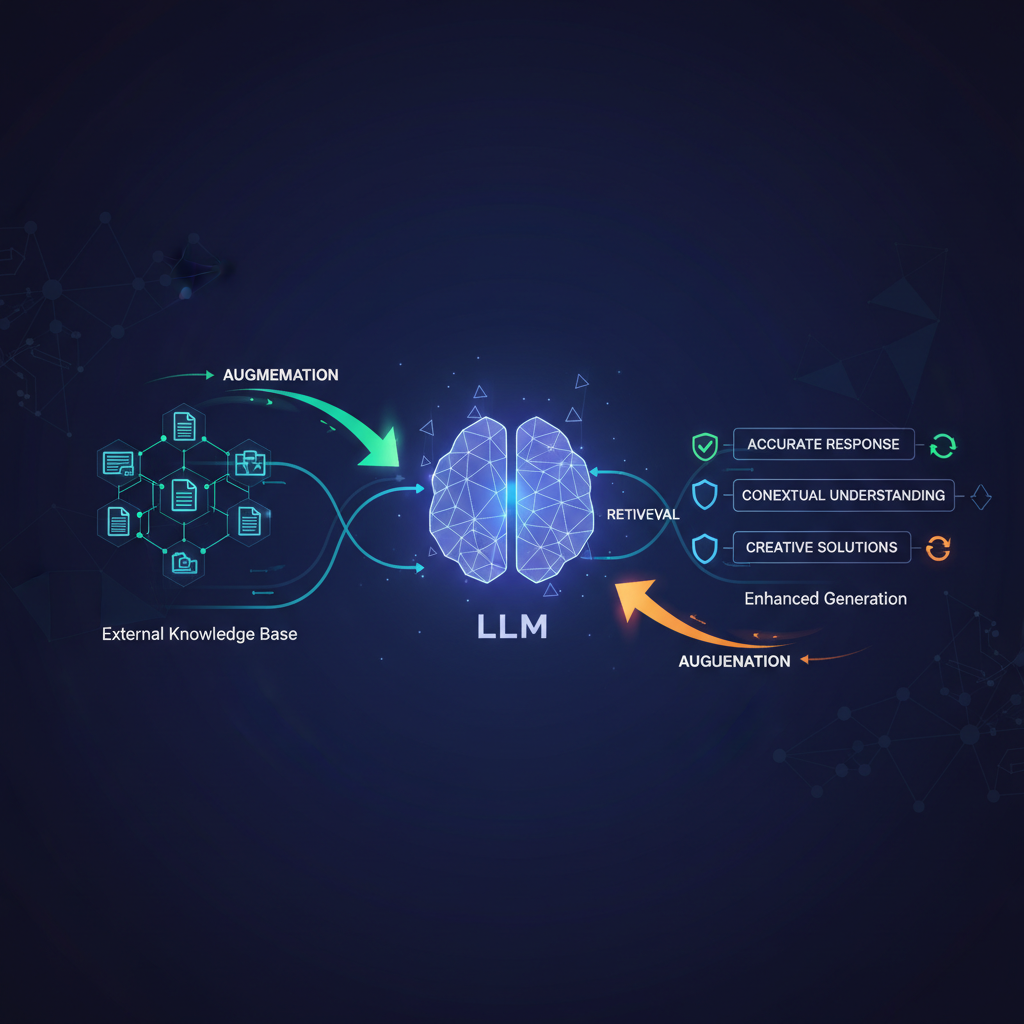
RAG directly tackles these issues by introducing an external, dynamic knowledge base that the LLM can query before generating a response. This simple yet profound shift grounds the LLM's output in verifiable, up-to-date information, making it more reliable, accurate, and trustworthy.
The RAG Architecture: A Deep Dive
At its core, RAG involves two primary phases: Retrieval and Generation.
1. The Retrieval Phase
This phase is responsible for finding the most relevant pieces of information from a vast external knowledge base, given a user's query.
1.1. Data Ingestion and Indexing: Before retrieval can happen, your knowledge base needs to be prepared. This involves:
- Data Loading: Gathering data from various sources (PDFs, websites, databases, internal documents, APIs, etc.). Tools like LlamaIndex offer a wide array of data loaders for this purpose.
- Text Splitting/Chunking: Breaking down large documents into smaller, manageable "chunks" or passages. This is critical because embedding models and LLMs have token limits.
- Fixed-size Chunking: The simplest approach, splitting text into chunks of a predefined token count, often with some overlap to maintain context.
- Semantic Chunking: More advanced methods aim to preserve semantic coherence within chunks. This might involve using natural language processing techniques to identify logical boundaries (e.g., paragraphs, sections, or even using an LLM to determine optimal splits).
- Recursive Chunking: Splitting documents into larger chunks, then recursively splitting those into smaller chunks if they are still too large, creating a hierarchy of information.
- Embedding Generation: Each chunk is then converted into a numerical vector (an embedding) using an embedding model (e.g., OpenAI Embeddings, Cohere Embed, Sentence-Transformers). These embeddings capture the semantic meaning of the text.
- Vector Database Storage: These embeddings, along with their original text chunks and metadata, are stored in a specialized database called a vector database (e.g., Pinecone, Weaviate, Milvus, Qdrant, Chroma). Vector databases are optimized for fast similarity searches.
1.2. Query Processing and Search: When a user submits a query:
- Query Embedding: The user's query is also converted into an embedding using the same embedding model used for the knowledge base chunks.
- Similarity Search: The query embedding is then used to perform a similarity search in the vector database. The database returns the top
kmost semantically similar text chunks to the query. This is typically done using distance metrics like cosine similarity. - Hybrid Search: Often, a purely semantic search might miss keyword-specific matches. Hybrid search combines vector search with traditional keyword-based search (e.g., BM25) to get a more robust set of initial results.
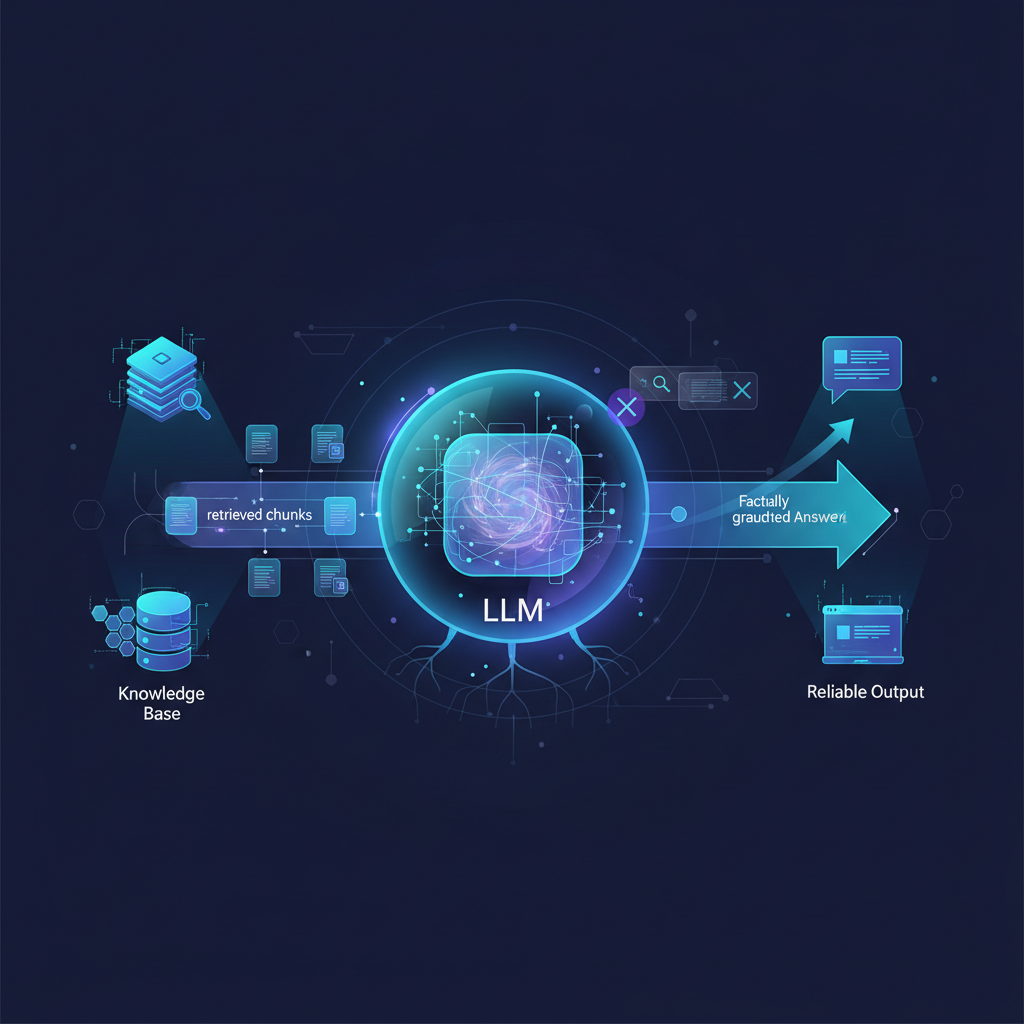
2. The Generation Phase
Once the relevant documents are retrieved, they are passed to the LLM along with the original user query.
-
Prompt Construction: The retrieved chunks are inserted into a carefully crafted prompt template, alongside the user's original query. A typical prompt might look like:
You are an expert assistant. Answer the user's question based ONLY on the provided context. If the answer cannot be found in the context, state that you don't have enough information. Context: [Retrieved Document 1 Text] [Retrieved Document 2 Text] ... [Retrieved Document N Text] User Question: [Original User Query] Answer:You are an expert assistant. Answer the user's question based ONLY on the provided context. If the answer cannot be found in the context, state that you don't have enough information. Context: [Retrieved Document 1 Text] [Retrieved Document 2 Text] ... [Retrieved Document N Text] User Question: [Original User Query] Answer: -
LLM Inference: The LLM then processes this augmented prompt. Because the relevant information is explicitly provided in the context, the LLM is guided to generate an answer that is grounded in the retrieved facts, significantly reducing hallucinations and ensuring factual accuracy.
Advanced RAG Techniques and Emerging Trends
The RAG landscape is evolving rapidly, with researchers and practitioners developing increasingly sophisticated methods to enhance its performance.
1. Advanced Retrieval Strategies
- Graph-based Retrieval: For highly structured or interconnected data, knowledge graphs can be incredibly powerful. Instead of just retrieving text chunks, RAG can query a knowledge graph to retrieve entities, relationships, and structured facts, providing a richer context to the LLM.
- Multi-modal Retrieval: As LLMs become multi-modal, so does RAG. This involves retrieving information not just from text, but also from images, videos, or audio, using multi-modal embedding models.
- Context-aware Chunking: Moving beyond fixed-size chunks, methods like "parent document retrieval" or using LLMs to identify optimal chunk boundaries ensure that retrieved context is semantically complete and coherent. For example, a small chunk might be retrieved, but its larger "parent" document or surrounding paragraphs are then fetched to provide more context.
- Query Transformation/Expansion:
- HyDE (Hypothetical Document Embeddings): The LLM first generates a hypothetical, concise answer to the user's query. This hypothetical answer's embedding is then used to retrieve documents, often leading to better semantic matches than the original short query.
- Query Rewriting: An LLM can be used to rephrase or expand the user's query to make it more effective for retrieval, especially if the initial query is ambiguous or too short.
- Sub-query Generation: For complex questions, an LLM can break it down into multiple sub-queries, perform retrieval for each, and then synthesize the results.
2. Sophisticated Re-ranking
Initial retrieval often returns a broad set of k documents. Re-ranking refines this set to present only the most relevant ones to the LLM.
- Cross-Encoder Re-rankers: After the initial retrieval, a smaller, specialized transformer model (a "cross-encoder") can re-score the relevance of each retrieved document against the query. Unlike bi-encoder embedding models (which embed query and document separately), cross-encoders process the query and document together, allowing for a deeper, more nuanced understanding of their relationship. Cohere Rerank and BGE-Reranker are popular choices.
- LLM-based Re-ranking: The LLM itself can be prompted to evaluate and re-order the retrieved documents based on their perceived relevance to the query, acting as a final filter.
3. Iterative and Adaptive RAG
These advanced approaches allow the LLM to interact more dynamically with the retrieval process.
- RAG-Fusion: This technique generates multiple query variations for a single user question, performs parallel searches using these variations, and then fuses the results using reciprocal rank fusion (RRF) to get a highly relevant set of documents.
- Self-RAG: In Self-RAG, the LLM doesn't just generate an answer; it also decides when to retrieve, what to retrieve, and how to integrate the retrieved information. It can even perform self-reflection, evaluating the quality of its own generated response and potentially triggering further retrieval or generation steps to improve accuracy. This introduces a level of agency into the RAG process.
4. Evaluation Metrics and Frameworks
Evaluating RAG systems is complex because it involves assessing both retrieval quality and generation quality. Frameworks like RAGAS and TruLens are emerging to provide metrics for:
- Retrieval Quality: Precision, recall, faithfulness (do retrieved docs support the answer?), context relevance.
- Generation Quality: Answer faithfulness (is the answer supported by retrieved docs?), answer relevance (does the answer directly address the query?), answer correctness.
Practical Applications and Use Cases
RAG is not just a theoretical concept; it's driving real-world impact across various industries.
-
Enterprise Search & Knowledge Management:
- Internal Q&A Systems: Companies can build intelligent chatbots that answer employee questions based on internal documents (HR policies, product specifications, engineering manuals, sales playbooks). This significantly reduces the time employees spend searching for information and improves onboarding.
- Example: A new employee asks, "What is the policy for remote work expenses?" The RAG system retrieves the latest HR policy document and provides a concise, accurate answer, citing the relevant section.
-
Customer Support & Chatbots:
- Enhanced Support Bots: RAG-powered chatbots can provide more accurate and helpful responses to customer queries by accessing up-to-date product manuals, FAQs, support tickets, and knowledge bases. This reduces the load on human agents and improves customer satisfaction.
- Example: A customer asks, "How do I troubleshoot error code E-205 on my smart thermostat?" The RAG system retrieves the relevant troubleshooting guide and provides step-by-step instructions.
-
Legal & Medical Research:
- Research Assistants: Professionals in highly specialized fields can use RAG to quickly find relevant case law, medical literature, research papers, or clinical guidelines, complete with direct citations. This accelerates research and ensures decisions are based on the latest evidence.
- Example: A lawyer queries, "What are the precedents for intellectual property infringement in software development?" The system retrieves relevant court cases and legal summaries.
-
Personalized Content Generation:
- Dynamic Reporting: Generating summaries, reports, or personalized content grounded in specific user data or external knowledge. This could range from financial reports based on real-time market data to personalized learning materials.
- Example: A financial analyst asks for a summary of Q3 market trends for the tech sector, pulling data from recent news articles and financial reports.
-
Educational Tools:
- Intelligent Tutors: Developing AI tutors that can explain complex concepts, answer student questions, and provide feedback based on specific textbooks, course materials, or curriculum standards.
- Example: A student asks, "Explain the concept of quantum entanglement using examples from my physics textbook." The RAG system retrieves relevant sections and generates an explanation.
-
Data Analysis & Reporting:
- Natural Language Interfaces for Data: Generating natural language summaries and insights from structured and unstructured data by retrieving relevant data points and contextual information from databases, spreadsheets, or internal reports.
- Example: A business analyst asks, "Summarize sales performance for the EMEA region last quarter, highlighting key drivers." The system queries sales databases and internal market analysis reports.
Key Technologies and Tools
Building a robust RAG system involves integrating several components:
- Vector Databases/Stores: These are specialized databases designed to store and query high-dimensional vectors (embeddings) efficiently.
- Cloud-native: Pinecone, Weaviate, Qdrant
- Self-hosted/Open-source: Milvus, Chroma
- In-memory/Local: FAISS (Facebook AI Similarity Search)
- Embedding Models: Convert text into numerical vectors.
- Proprietary: OpenAI Embeddings, Cohere Embed
- Open-source: Sentence-Transformers (e.g., all-MiniLM-L6-v2), BGE (BAAI General Embedding), E5
- Orchestration Frameworks: Simplify the development and management of RAG pipelines.
- LangChain: A versatile framework for chaining together LLM components, including retrieval, generation, and agents.
- LlamaIndex: Specifically designed for RAG, offering powerful data ingestion, indexing, and query capabilities over various data sources.
- Re-rankers: Improve the relevance of retrieved documents.
- Proprietary: Cohere Rerank
- Open-source: BGE-Reranker
- Data Loaders/Connectors: Facilitate getting data into your RAG system. LlamaIndex, for example, offers a vast ecosystem of "readers" for PDFs, Notion, Confluence, Google Docs, databases, and more.
Conclusion
Retrieval-Augmented Generation has emerged as a transformative architectural pattern for deploying Large Language Models in practical, production-ready applications. By directly confronting the challenges of hallucinations, stale knowledge, and lack of transparency, RAG empowers developers to build LLM-powered systems that are not only intelligent but also reliable, factual, and trustworthy.
The rapid innovation in retrieval strategies, re-ranking techniques, and adaptive RAG approaches continues to push the boundaries of what's possible. For AI practitioners and enthusiasts alike, mastering the principles, architectures, and tools of RAG is no longer optional; it's becoming an essential skill for anyone looking to harness the true potential of LLMs in solving real-world problems. RAG is not just augmenting generation; it's augmenting the future of practical AI.